
在前面的一篇文章Linux网络优化之链路层优化中,我们已经看到,随着网卡速率超过1Gbps,增加到10Gbps/100Gbps时,CPU已经很难处理如此大量的数据包了。总结来说,主要有如下瓶颈:
- 内核协议栈处理在
L3(IP)/L4(TCP)的数据处理上,消耗了比较多的时间,会导致网络延迟与传输受限 - 高速网卡会在短时间内产生大量中断,导致CPU频繁发生上下文切换,性能收到影响,进而影响网络吞吐
针对10Gbps/100Gbps等高速网卡中存在的延迟与带宽受限问题,Intel在2010年提出了DPDK(Data Plane Development Kit)基于用户空间的解决方案,并开源了实现方案, 目前DPDK支持包括Intel/ARM等多个芯片架构的指令集; 同样是Intel的工程师在2018年提出了XDP(eXpress Data Path),与DPDK不一样的是,XDP基于现有内核socket接口,与eBPF相结合实现网卡与用户空间的数据传输,从而避免了内核协议栈的处理延迟。
下面我们来简单看下DPDK与XDP的实现原理。
本文主要是简要介绍基本原理,收集一些参考资料
DPDK(Data Plane Development Kit)
DPDK是由一系列开源库组成的用于网络加速的工具集,其提供了数据平面(data-plane)以及用户空间基于poll模式的网卡驱动,以跳过内核TCP/IP协议栈, 加速网络数据的传输。DPDK为如PowerPC/Arm/x86等多个平台提供了一个框架,用于高速网络情况的数据处理,常用在数据中心节点之间的数据传输。
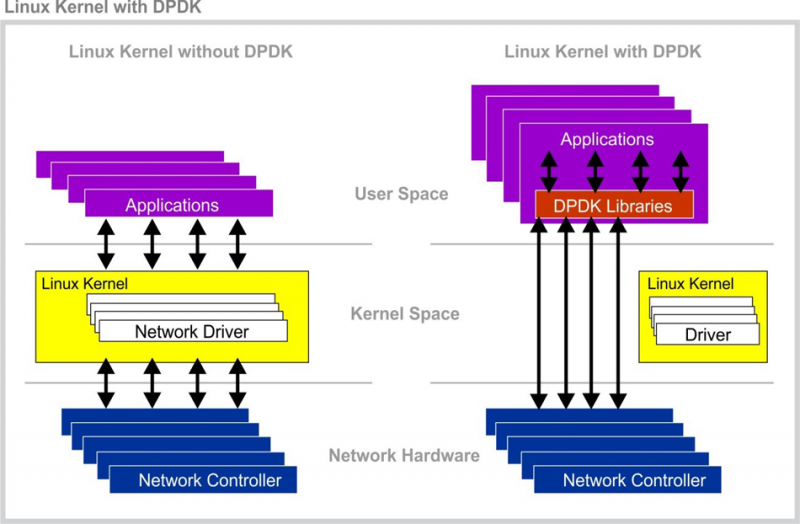
有关更多DPDK实现原理与细节可以参考如下资料:
- Wikipedia DPDK
- Network Acceleration with DPDK
- Linux development Guide
- Deep-dive into DPDK
- DPDK Sample Applications
- DPDK source code
XDP(eXpress Data Path)
XDP方案与DPDK类似,都是尝试跳过内核协议栈从而加速数据包的处理,只不过XDP是基于内核已有的socket接口来实现,其增加了一个AF_XDP的地址类型,用户进程可以通过AF_XDP的接口来实现与内核的交互, 比如映射接收数据包的共享内存,加载接收网卡数据包的BPF内核程序(有关内核BFP可以参考BPF与eBPF)。

从XDP的实现原理来说,相比于DPDK, XDP更贴近Linux内核,因而使用起来更为方便,而且其总体性能可以接近于DPDK。有关XDP实现原理与细节可以参考如下资料:
- Introduction to XDP
- Accelerating networking with AF_XDP
- Kernel networking-XDP
- DDos Mitigations based on XDP
- Get started with XDP
- AF_XDP kernel patch