
深度学习(Deep Learning)是近年来人工智能的热门研究领域, 广泛地应用在工业与商业领域, 如计算机视觉(Computer Vision), 语音识别(Speech Recognition), 自然语言处理(Natural Language Processing), 机器翻译(Machine Translation), 以及医学图像分析, 药物发现等领域都采用了深度学习方法. 从本质上来说, 深度学习属于机器学习(Machine Learning)的一个分支, 是一种从大规模数据进行学习然后能在新数据集进行推理泛化的数学模型.
相比人工智能, 深度学习只是最近十来年才出现的概念, 但为何会在在最近几年(2010开始)内出现井喷式的增长, 成为人工智能领域炙手可热的研究方向了? 总结来说主要有如下几个原因:
- 数据集: 随着大型互联网公司的出现, 大规模的数据集变得触手可得
- 物理设备: 存储设备容量更大, 价格更便宜, 能够保存更多的数据; GPU等支持并行计算的专用处理器为深度学习模型的训练提供必要的物理基础, 让模型训练时间更短
- Google/Facebook等公司开源了
Tensorflow/Caffe/PyTorch等开源了深度学习的框架, 为深度学习的应用与传播起到了重要的推动作用
深度学习核心思想来自于人工神经网络(Artificial Neural Network), 但从结构上来说, 深度学习网络具有更多的层级, 网络结构更为复杂, 存在前馈/循环以及深度生成对抗网络等多种形式, 因此并不与神经网络等价, 可以看作是神经网络的升级版. 从技术的范畴来说, 深度学习是机器学习的一个子集, 而机器学习是人工智能(Artificial Inteligence)的一个分支而已.

这篇文章旨在对深度学习的历史以及基本概念做梳理, 可能有很多疏漏跟错误的地方, 感兴趣的同学可以自行参考文末的文献进行深入了解.
人工智能的发展历程
人工智能是人类尝试通过计算机模拟生物智能尤其是人类智能活动, 从而实现机器智能的目标. 人脑经历上千万年的进化才得以形成如此复杂的结构, 想要让机器具备人一样的智能, 机器需要拥有感知(计算机视觉, 语音识别), 学习(模式识别, 机器学习, 强化学习), 语言(自然语言处理), 决策(规划, 数据挖掘)等多种能力. 而这些都构成了人工智能的研究领域.
一般来说, 人工智能的研究领域大致可以分为如下几个部分:
- 感知(
perception): 模拟生物的感知能力, 对外部信息如视觉/听觉进行处理加工, 主要研究领域包括计算机视觉和语音信息处理等 - 学习(
Learning): 模拟生物的学习能力, 研究如何从已有数据集或从与环境的交互中进行学习, 研究领域包括监督学习(Supervised Learning), 无监督学习(Unsupervised Learning)以及强化学习(Reinforcement Learning)等 - 认知(
Cognition): 模拟生物的认知能力, 研究领域包括知识表示, 自然语言理解, 推理/规划/决策等
自人工智能诞生以来, 大致经历了三个重要的发展阶段:

- 推理期: 1956年达特茅斯的人工智能会议后, 相关的研究开始涌现出来. 研究者基于逻辑或者事实归纳出来一系列规则, 基于这些规则通过编程尝试让计算机完成某些特定的任务. 但当时的人们过于乐观, 也低估了人工智能系统实现的难度, 很多项目难以达到预期的目标. 人工智能的研究在之后的数年时间陷入了低谷, 很多研究项目被中止, 经费被削减.
- 知识期: 到20世纪70年代, 人们开始意识到知识对人工智能系统的重要性. 这一时期开始出现很多专家系统(
Expert System), 并在特定的领域取得了很多成果. 专家系统一般采用知识表示和知识推理来完成由领域专家才能解决的问题. 为了解决这些问题, 人们开发出了Prolog(Programming in Logic)语言来构造专家系统/知识库以及实现自然语言理解等. - 学习期: 到这个阶段, 研究者尝试利用数据让机器自动学习, 即采用机器学习(
Machine Learning)的方式让计算机从数据(经验)中学习并获得规律(模型), 然后再利用该模型在未知的数据集上进行预测推理.
人工智能的发展距今已经超过60年, 大数据与深度学习方法的结合让原本看来很困难的问题, 如图像识别, 语音识别, 机器翻译等变得更加容易, 甚至在某些特定的领域这些深度学习模型能够超越人类的表现. 但要想真正实现与人同样的智能程度, 还有很多的困难需要解决, 还有很长的路要走.
机器学习
机器学习(Machine Learning)是指从有限的观测数据中学习出具有一般性的规律(找出数据中模式), 并利用这些规律对未知的数据进行预测的方法. 国际机器学习大会的创始人之一Tom Mitchell对机器学习的定义是:计算机程序从经验 E 中学习,解决某一任务T,进行某一性能度量P,通过P测定在T上的表现因经验E而提高.
要训练一个机器学习模型, 通常包含如下几个部分:
- 数据(
data): 用于训练模型与验证模型的数据集. 数据集由一个个样本(sample)组成, 大多数时候, 这些样本都遵循独立同分布(Independently and Identcally Distributed), 每个样本通常由一组特征(features, 也称为协变量-covariables)组成. 机器学习模型会根据这些属性进行预测. - 模型(
model): 模型是对给定数据集的抽象表示, 可以看作参数化的数学模型. - 目标函数: 要想从数据中学习到某种规律(经验), 首先要有一种度量模型质量的方法, 在大多数情况下, 这个模型度量是可优化的, 我们称之为目标函数(
objective function), 也称为损失函数(loss function/cost function). 通常, 目标函数是根据模型参数定义的, 并取决于数据集. 为了确保模型在未知的数据上具备足够的泛化能力(generalization), 通常需要将数据集划分成训练集(training set)和测试集(test set)两个部分. 训练集用于训练模型, 而测试集用于验证模型的能力. 如果一个模型在训练集上表现很好, 但在测试集上却表现比较差, 我们称这种情况为模型过拟合(over-fitting); 有时在训练模型的过程中, 通常还需要将数据集分出一部分用于验证评估模型的质量, 这部分数据集就称为验证集(validation set). - 模型优化算法: 模型训练的过程, 其实就是对模型参数进行搜索, 从而最小化目标函数. 比如常用的梯度下降(
gradient descent)算法, 在每个步骤中, 会对每个参数沿着目标函数减小的方向(对应的梯度是下降的)进行调整, 直到目标函数达到某个局部最小点或者全局最小点.
按类别来说, 机器学习一般来说分为监督学习, 非监督学习和强化学习三种:
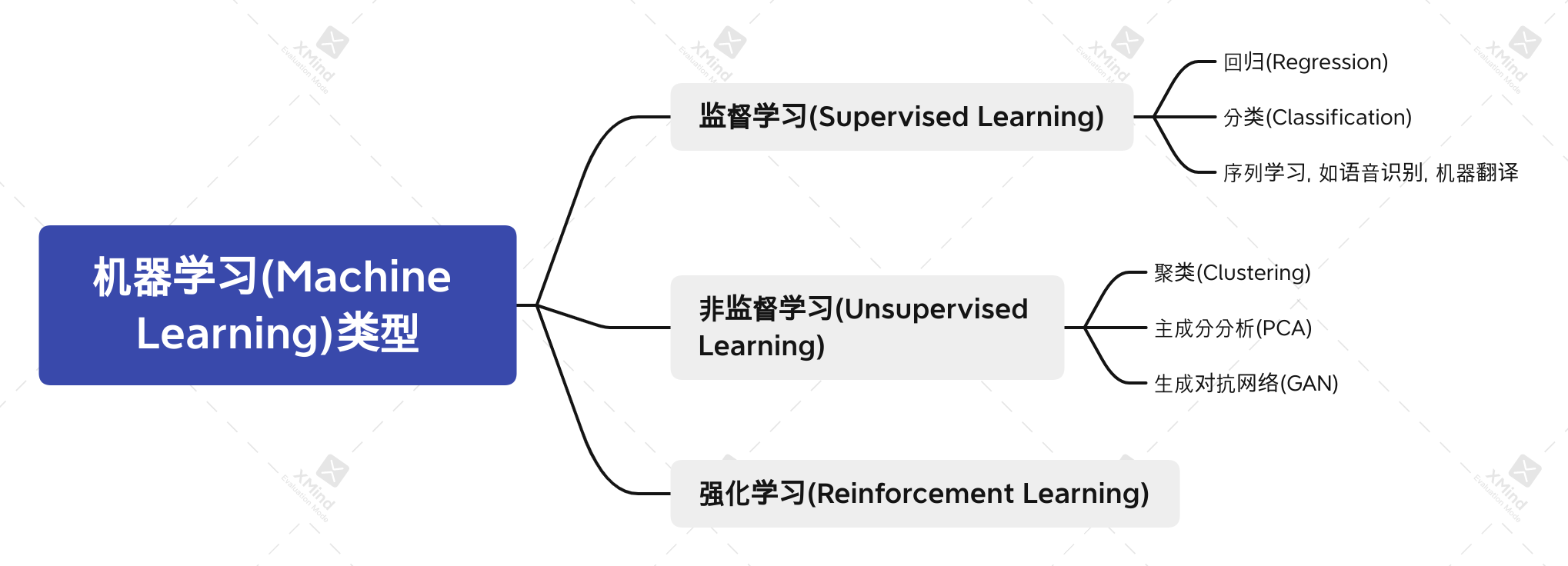
- 监督学习(
supervised-learning)是指在一组特征(feature, 输入)与标签(label, 输出)的情况下对特定输入特征进行预测的一类算法, 常见的有回归, 分类, 以及序列学习等.

无监督学习(
unsupervised learning), 与监督学习不同的是, 只有输入特征, 却没有一个可以参考的输出标签; 需要从这些数据中找出特定的关系, 挖掘数据内在的联系. 比如在没有标签信息的情况下, 如何把一堆图标分类成风景, 动物, 婴儿等; 找到较少的参数来描述数据中的线性关系, 从不同的数据中找到相关性. 常见的有聚类分析, 主成分分析, 以及概率图模型/生成对抗网络等.强化学习(
reinforcement learning): 上述两种方法都采用的是预先获取到的经验数据来训练模型, 并没有从外部环境交互中获取数据, 因此是离线学习(offline learning). 与此不同的是, 强化学习中的agent会通过观察者(observation)不断与环境进行交互, 然后从中获得奖励reward,agent根据奖励来调整自己的执行动作action, 以输出一个更好的策略.这个过程会随着系统与外界环境交互持续进行. 强化学习是一个十分强大的通用性学习框架, 打败世界围棋冠军的AlphaGo就是基于强化学习开发的.
人工神经网络与深度学习
说到深度学习, 就不得不提人工神经网络(Artificial Neural Network), 因为正是有了前期人工神经网络的技术积累, 尤其是多层网络的训练算法-反向传播算法(backpropagation),才有了深度学习今天的广泛应用.
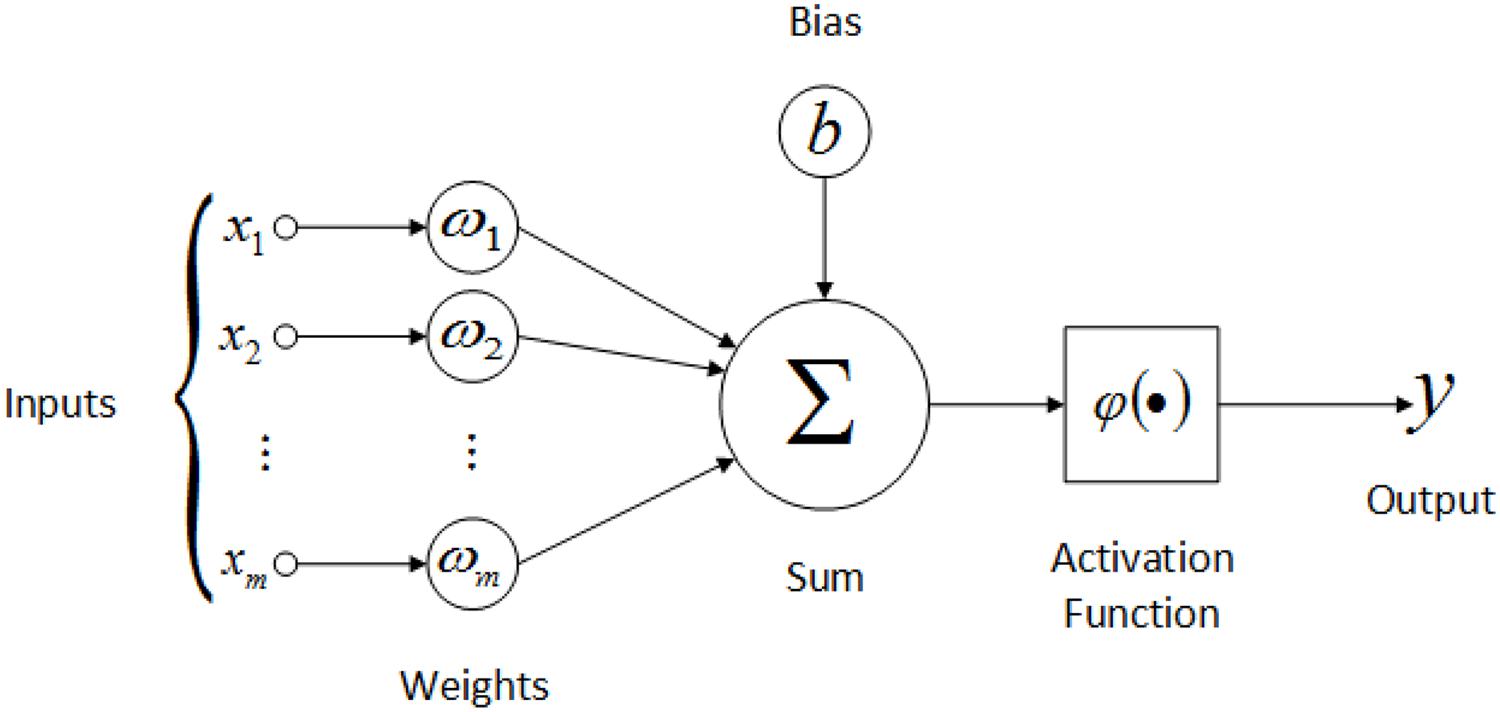
人工神经网络基本的单元-人工神经元(neuron)本质上是模拟大脑的神经元构建出来的, 一般由三个部分组成: 输入(inputs), 激活函数(activation function)以及输出(outpus), 写成数学表达式如下:
$$y = \varphi(\sum_{i=1}^{m} w(i) * x(i) + b)$$
人工神经网络是在单个神经元的基础上做了扩展, 引入了一个隐藏层(hidden layer), 从而形成一个多层的结构, 这个就类似于人脑的神经网络了: 网络通过从数据中获取知识, 每个神经元的权重值保存了学习到的知识. 人工神经网络具有较强的拟合能力, 可以看作一个通用的函数逼近器(一个两层的神经网络可以逼近任意函数).
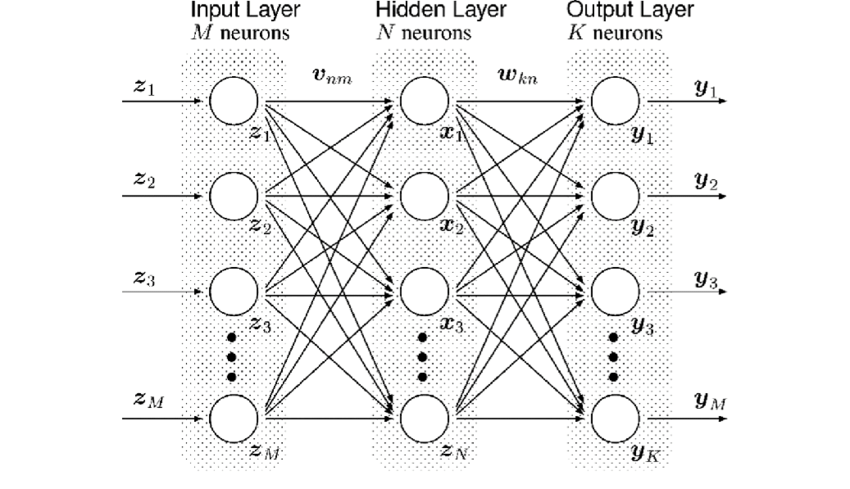
深度学习(Deep Learning)是在人工神经网络的基础上发展而来, 只是在网络结构上引入了更多的隐藏层, 网络的结构也更为多样复杂. 常见的网络结构有前馈网络, 记忆网络以及图网络:
- 前馈网络(
feedforward neural network): 各个神经元属于不同的层, 每一层可以接收上一层的输出为输入, 并产生信号输出到下一层. 网络的第0层为输入层, 最后一层为输出, 其他层均为隐藏层. 常见的前馈网络有卷积神经网络(Convolutional Neural Network) - 记忆网络: 记忆网络也称为反馈网络(
feedback network), 网络中的神经元不但可以接收来自上一层神经元的信息, 也可以接收来自自身的信息; 记忆网络中的神经元具有记忆功能, 在不同时刻具有不同状态. 常见的记忆网络有循环神经网络(Recurrent Neural Network), Hopfiled网络, 波尔兹曼机(boltzmann machine)等. - 图网络: 前馈网络和记忆网络的输入都可以表示为向量或向量序列,但在实际应用中, 如知识图谱, 社交网络, 分子(molecular)网络等都是图结构的数据, 这类数据网络需要用图网络来学表达. 在图网络中, 每个节点由一个或一组神经元构成, 节点之间的连接可以是有向的, 也可以是无向的, 每个节点可以接收来自相邻节点或者自身的信息. 常见的图网络有图卷积网络(
Graph Convolutional Network), 图注意力网络(Graph Attention Network)等.

总结
深度学习从概念的出现到今天的大规模应用, 也不过20来年的历史, 但已经在图像识别, 语音识别, 自然语言处理等各个方面都取得了令人惊讶的成绩, 基于深度学习的AI模型不仅可以准确识别图像, 也可以在围棋上战胜人类冠军; 可以与人展开对话, 也可以执行自动驾驶的功能. 未来, 随着大数据与AI技术的发展, 深度学习会在更多的行业与领域得到更广泛的应用. 近年来, 基于多个机器学习模型的多模态技术(multimodal machine learning)的逐渐发展, 在很多领域都取得了不错的成果. 相信在不久的将来, 无论是手机终端, 还是汽车/飞机都会有深度学习的身影, 在人类生活的各个方面都发挥至关重要的作用.未来会是一个基于大数据的智能化时代-一个大数据与深度学习等人工智能技术紧密结合的智能化时代.