
最近了解Linux的性能优化时, 接触到了BPF(Berkeley Packet Filter)。很有意思也很强大的功能;想把学到的一些基本原理与知识记录下来, 算是一个初步的总结. 这篇文章主要从如下几个方面介绍下BPF:
- BPF的原理
- 什么是eBPF
- 如何在Linux中使用BPF
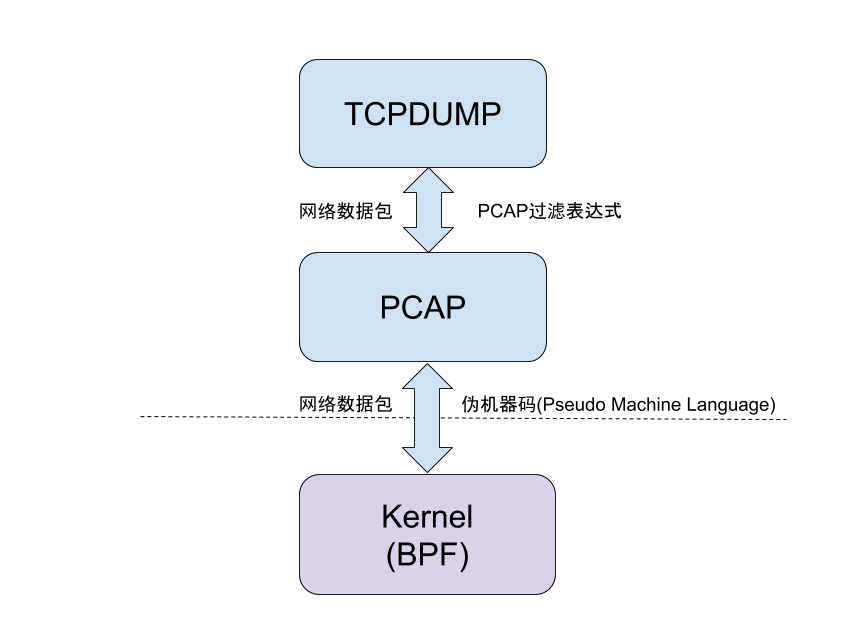
用过tcpdump的同学应该都了解pcap, 实际上pcap就是基于BPF来实现网络数据包的过滤的. tcpdump的原理如下图所示: tcpdump将包过滤的表达式, 如查看某个网口所有udp包, 输入tcpdump -n -i eth0 udp, 这个表达式通过PCAP库编译成伪机器字节码后, 通过系统调用发送给内核(内核中有对应的机器码解释器)解释执行, 这样只要系统有udp包, 内核都会过滤出来转发给用户进程tcpdump:
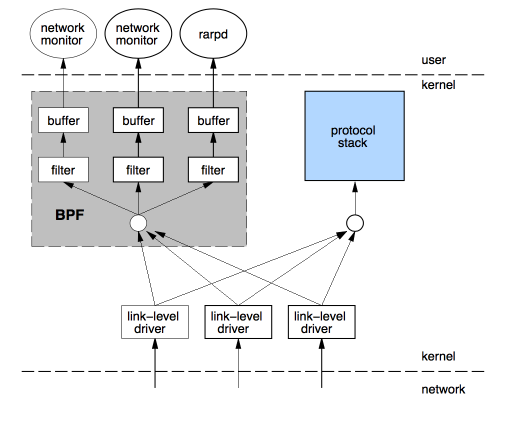
BPF全称Berkeley Packet Filters, 最初是Steven MaCanne, Van Jacobson在文章‘The BSD Packet Filter: A New Architecture for User-level Packet Capture’中提出的一种基于BSD Unix操作系统的包过滤器, 其原理是将包过滤的表达式编译成特定伪机器码后, 由Kernel中的虚拟机执行; 每当网卡中有数据包过来时, 将其拷贝发送给BPF模块, 由BPF根据对应的过滤条件将过滤后的包发送给用户进程:
针对tcpdump, linux有专门用于包过滤的表达式, 参考
pcap-filter
BPF在Linux中的发展大致经历三个阶段:
- Linux 2.1.75最初的实现基于原有的socket接口, 被称为
Linux Socket Filter(LSF) - Linux 3.0版本中,在BPF中加入JIT(
Just-In-Time Compiler), 提升BPF的性能与速度 - Linux 3.15开始将BPF扩展成为通用的模块, BPF不仅可用于数据包过滤, 也可以用来进行内核事件跟踪/应用性能调优/流量控制(Traffic Control)等, 代码也统一整合到了
/kernel/bpf, 这也是目前被称为eBPF(extended BPF)的原因, 而早前的BPF实现则被称为cBPF(classic BPF).
首先来看下传统的cBPF是如何实现的.
cBPF
BPF最初的BSD实现方案是通过打开一个字符设备/dev/bpf*(/dev/bpf0, /dev/bpf1 etc), 再通过ioctl来控制该设备, 而Linux内核则基于现有的socket接口加入新的选项SO_ATTACH_FILTER/SO_DETACH_FILTER来执行系统调用, 具体的代码实现在/net/core/filter.c. 通过一个简单的示例来看下cBPF是如何工作的.
- 首先通过
tcpdump指令来产生数据包的过滤代码:tcpdump dst port 53 -dd(这里过滤所有目标端口为53的数据包) - 然后创建一个
AF_PACKET(用于接收所有的数据包)的socket用于向kernel传递过滤代码, 并接收过滤后的数据包
1 |
|
刚才说到在Linux 3.0版本中BPF加入了JIT; JIT能够提升伪机器码的执行效率. 从执行流程来说, 主要区别在于传入内核的socket_filter伪机器代码都会通过bpf_jit_compile进行优化处理, 然后再通过字节码解释器执行. 具体来说, 不同的平台bpf_jit_compile的实现不一样, 内核中的代码路径位于arch/<platform>/net/, 感兴趣的可以参考这个链接这里看下.
eBPF
eBPF即extended BPF, 顾名思义是对原有BPF进行了扩展, 这样不仅BPF可以用来过滤网络数据包(tcpdump/XDP), 也可以用于性能分析, 将BPF代码插入到内核的跟踪点(tracepoints), kprobes, perf事件, 收集相应的数据.除了扩展了cBPF的功能外, eBPF另一个不同于cBPF的地方在于调用的方式: eBPF提供了一个统一的bpf()系统调用来执行相应的操作,同时应用与内核的数据传递也统一通过map这种数据结构来进行. 比如用BPF_MAP_CREATE命令来创建一个eBPF的map对象(不同的内核事件对应的map类型不同):
1 |
|
我们可以通过man bpf来查看bpf系统调用的具体用法. eBPF对于内核的开发, 以及性能分析无疑是一大利器, 先通过具体的实例来看一看如何使用eBPF(Linux源码中有很多示例samples/bpf):
1 |
|
可以看到,对于eBPF而言, 大概有如下几个执行步骤:
- 编写ePBF伪机器代码
- 调用
bpf创建对应的map对象, 并将伪机器码加载到内核 - 内核对加载得到伪机器码进行优化/校验, 验证其是否合法(是否有非法指令, 加载的程序是否兼容
GPL兼容协议等) - 用户程序通过
bpf的接口读取内核事件的结果
这个例子用的是类似汇编语言的方式来实现eBPF伪机器代码, 这个对于非专业的开发者来说实在有点痛苦. 那么, 能否通过其他高级语言来编写eBPF的代码了? 这就要用到专门的编译器LLVM(Lower Level Virtual Machine)了.通过LLVM, 我们只需要将需要执行的eBPF代码用C语言编写好后, 将其编译成elf格式的镜像(image)文件, 然后通过libelf库加载解析后, 装载到内核中执行. 如果去看samples/bpf中的其他示例, 都是通过类似的方式实现的.
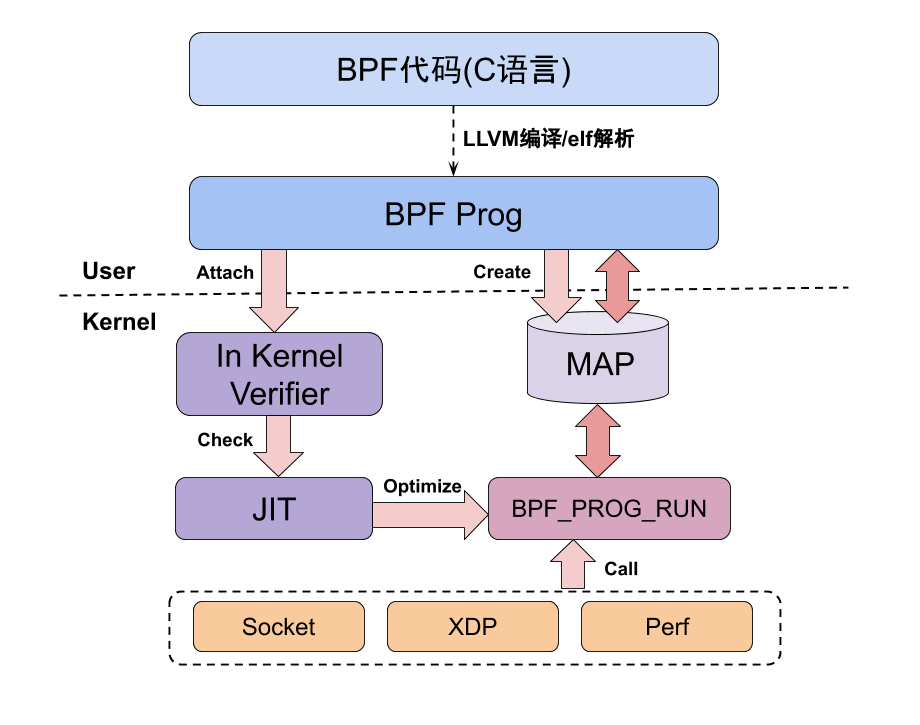
了解了eBPF大致的执行流程, 我们一起来看下eBPF原理的框架简图(eBPF涉及的内核知识比较多, 刚开始建立一个整体的框架有助于理解):
BCC
即使有现成的编译工具LLVM, 有加载解析elf的库, 但对大部分开发者来说, 日常并没有太多时间精力一步步来开发这些eBPF工具与代码. 于是, 一些大牛们便搞出了一套BCC(BPF Compilation Collection)的eBPF工具集合, 这个工具集合把所有eBPF内核代码编写/编译以及错误处理的流程都封装好了, 使用时只需通过python/Lua等脚本语言进行调用,这里从BCC的示例中选出一个简单的例子, 可以看到BCC极大的简化了eBPF的开发与使用流程:
1 |
|
如果Linux内核版本在4.4以上(如Ubuntu 16.04等), 可以通过如下指令安装BCC使用:
1 |
|
相应的, BCC的工具会安装到/usr/share/bcc/tools下面.更多BCC功能的解锁说明可以参考Brendan D.Gregg性能优化大牛的eBPF介绍以及BCC的[官网]https://github.com/iovisor/bcc). 安装完成后, 无论是对CPU, 内存, 磁盘I/O还是网络数据的传输都可以利用这一套工具进行监控了.
BPF相关的内核代码路径主要有如下几个,感兴趣的可以自行研究下:
kernel/bpf/: BPF核心代码,系统调用、trace跟踪、数据结构、程序校验等在这里实现net/core/filter.c: socket过滤的BPF功能kernel/trace/bpf_trace.c: trace相关功能的BPF入口