
TCP(Transmission Control Protocol)即传输控制协议, 位于TCP/IP协议栈的第三层传输层, 与UDP不同的是, TCP号称提供有链接的(connection-oriented), 可靠的(reliable)字节流服务, 很多其他应用层协议如HTTP/SMTP/MQTT都是基于TCP协议实现.
这篇文章我们就从定义的角度来看一看TCP协议的具体工作原理. 首先看下有链接的(connection-oriented)具体含义.
TCP在发送数据之前, 第一件事情就是要在通信的双方建立一个通信的链路, 这个有点像日常生活中的打电话: A向B发起通话请求, B确认后双方建立通信链接才能正式通话. TCP也一样, 在发送任何数据之前必须要建立链接(connection), 这个建立通信链接的过程就是我们常说的”三次握手”;同样, 如果要想结束通信, 也需要有一个挥手的过程(四次挥手).有关TCP链接的建立与关闭可以参考之前的一篇文章(TCP的链接建立与状态迁移). 那么, TCP建立链接主要完成哪几件事情了?
- 交换双方的
ISN(Initial Sequence Number): ISN的作用(后面在讲重传时会再讲到)是用来确保每个TCP数据包都是唯一的, 接收端如果收到了重复包可以根据每个包的序列号来实现去重 - 确认发送数据的
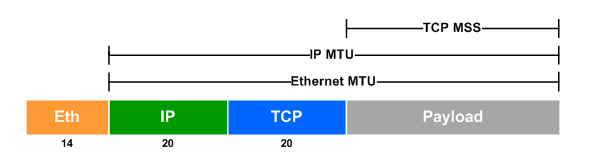
MSS(Maximum Segment Size): MSS是TCP能发送的数据的最大值, 通过TCP头中的options交换, 默认值是536, 一般是当前系统MTU(Maximum Transmission Unit)的值减去TCP/IP协议头的大小之和(40byte), 其与MTU关系如下图所示
- 接收窗口的大小: 在TCP头中有一个
window选项, 用来告诉对端自己接收缓冲区的大小, 这个窗口在拥塞与流量控制中扮演着十分重要的角色, 用于告诉发送方最大可以发送的数据大小
通信双方在三次握手完成之后, 都知道了对方的初始序列号(ISN), 接收窗口大小以及MSS, 这样发送方就可以开始愉快的发送数据了. 接着讲第二个方面: TCP是如何做到要数据的可靠(reliable)传输的? 为了实现这一目标,TCP需要解决很多问题:
数据在网络上丢包了如何办? TCP对于每个数据包都有个定时器, 如果接收方长时间没有回应, 在定时器超是后就会发起重传, 那么如何选择这个定时器的时长? 重传时间(Retransmission Timeout, RTO)太长, 导致数据传输效率太低; RTO太短, 则可能导致重传的数据包太多, 引发更大的网络拥堵.
发送方如何来控制自己数据的发送速率, 确保接收方能够处理的过来. 发送方不能不顾一切的发送数据, 而不管接收方是否有足够的空间来接受数据. 因此, TCP在接收方忙/没有足够空间接收数据时都会主动降低发送速度, 让接收方可以有机会及时恢复.这个是TCP流量控制(
flow control)需要做的事情.如果网络发生拥塞, TCP应该如何处理?发送端不能不顾及网络带宽以及拥堵状态而只管发送数据包, 进而影响其他用户正常使用网络.为了体现网络使用的公平性, 确保不同用户能够都能均衡的使用网络, 减少用户之间的相互干扰, TCP通过多种拥塞控制(
Congestion Control)手段来减少网络拥堵, 并且在发生拥堵时尝试尽快恢复.
具体说来TCP主要通过如下几个方式来解决上述几个问题:
- 重传时间的计算: 如何实时调整RTO(
retransmission timeout)的大小, 确保重传的频率在合适的范围 - 流量控制(
flow control): 通过滑动窗口(sliding window)机制来实现数据发送的流量控制 - 拥塞控制(
Congestion Control): 拥塞控制主要有 (1) 慢启动 ; (2) 拥塞避免; (3) 拥塞发生; (4) 快速恢复. 在后面会一一介绍这几个算法的原理.
何时重传
为了确保数据的可靠传达, TCP每发送一个数据包, 接收方都要回应一个ACK包, 发送方在发送完一个数据包后就会启动一个重传定时器(retransmission timer), 如果在定时器超时后都未能收到对方的ACK包, 就会重传. 那么如何发送方如何知道重传的超时时间(Retransmission Timeout, RTO)? (在TCP的标准协议文档RFC793中给出了一个低通滤波的计算方式, 式中alpha一般为0.9, RTT(Round Trip Time)表示测量得到的返程时间, R表示平滑后的RTT:
$$R = \alpha R + (1 - \alpha)RTT$$
而RTO是在平滑后的RTT乘以一个系数beta(一般取值为2)得到:
$$RTO = \beta R$$
按照上述的计算得到RTO, 由于采用低通滤波,因而没有考虑到在网络发生波动(比如网络拥堵, 路由故障等)等情况下RTT变大的情况, 导致不必要的重传, 反而带来更大的网络负载, 导致网络陷入持久的拥堵.针对该问题, Jacobson在1988年提出了一个改进的RTO计算方法(链接, 该算法考虑到了由于网络波动导致的延迟, 因此可以更准确的反映网络拥塞状态:
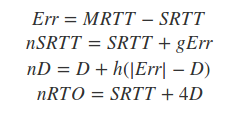
上述公式, MRTT代表实际测量得到的RTT, SRTT表示平滑后的RTT值, D实际表示的是RTT的平均方差(不是平方差), g一般设为1/8(0.125), 而h设为0.25.对于发生了重传的情况, RTO一般会通过指数回退的方式进行倍乘(Karn and Partridge 1987).
流量控制: 如何控制发送速率
收发数据的两端常常在网络带宽以及性能上都存在差异, (快的)发送方如果不控制发送的速度, 可能会让处在慢速网络中的接收方不知所措.因此, 为了实现数据的可靠传输, TCP需要根据接收方的信息及时调整发送速率, 这个控制发送流量的技术就是著名的滑动窗口(sliding window)协议.简单地讲, 滑动窗口是要根据接收方的可用window(TCP缓存)的大小来达到调整接收方流量大小的目的, 下图是一个滑动窗口示意图(图片来自TCP/IP Guide):
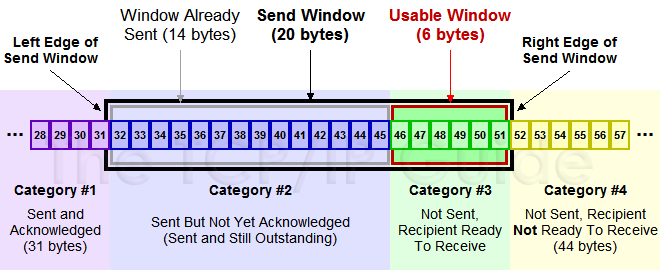
图中的数据主要分为4个部分:
- ‘#1’: 表示已经发送的数据, 并且收到了ACK
- ‘#2’: 表示发送了的数据, 但是没有收到ACK确认
- ‘#3’: 尚未发送的数据(接收方还有空间)
- ‘#4’: 不可发送的数据(接收方没有足够空间, 无能为力)
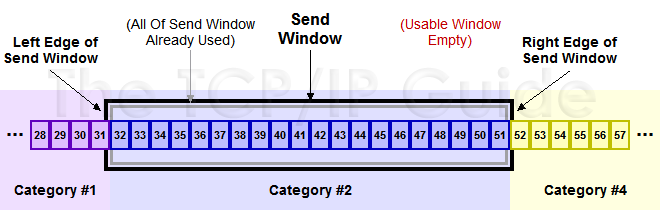
当发送了部分#3的数据更新后的滑动窗口如下图所示(图片来自TCPIP Guide):
可以看到此时可用的部分窗口大小变成了0, 后续要等到接收方确认了#2部分的数据后, 窗口才会继续往前滑动.那么TCP协议是如何在数据传输过程中调整窗口大小(window size)的了? 了解TCP协议的人应该记得, 在TCP协议头有一个专门的字段window用于通信的两端来告知对方当前窗口的大小(能接收多少数据), 而通过socket的SO_RCVBUF参数可以来设置通信时接收缓冲区的大小(socket(7)). 下图是一个接发数据过程通信两端TCP窗口大小的更新过程:
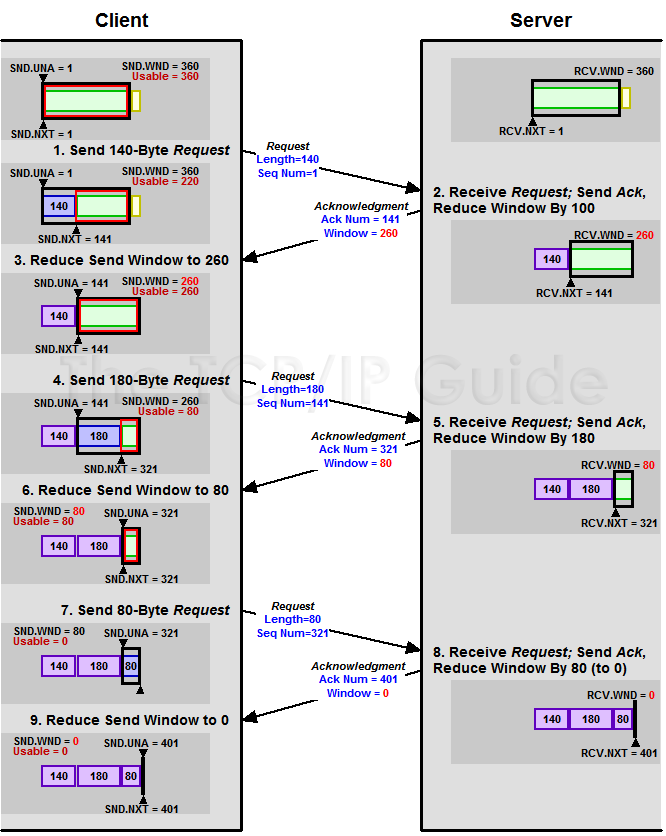
- 在发送数据的开始, 接收端会在三次握手时告知发送端自己的
window size(图中为360) - 随着发送端不断发送数据, 接收端的
window会逐渐减少, 直到为0, 此时发送端会暂停发送数据
问题来了, 如果接收方的window为0, 要如何处理?对于接收端, 在接收缓冲区可用后(如应用从读取了部分数据), 会发送一个window update的ACK包, 那万一这个ACK在传输过程中丢失了怎么办? 这样就会导致发送端的TCP无法正常关闭, 因此需要通过在发送端每隔一段时间就发送一个Zero Window Probe的探测包, 来获取接收端窗口的状态, 关于ZWP的说明可以参考(RFC1122)的讨论.
Silly Window Syndrome
Silly Window Syndrome(糊涂窗口综合症)的意思是, 接收端的应用可能每次都只拿走很少的一部分(比如几个字节)的数据, 因此每次window update后发送端也只会发送几个字节的数据, 而我们知道, 光TCP+IP两个协议头都需要40个字节的空间,这样的传输效率看起来太低了.针对该问题, 有两种策略:
如果问题发生在接收端(接收端处理太慢等), 则可以在
window小于某个值时, 直接向发送端ACK一个window=0的包, 告诉发送端暂停发送, 等window大于某个值(比如MSS/2)时再发送window update包让发送方继续发送数据;而如果问题发生在发送方,则可以考虑Nagle在1984年提出的
Nagle AlgorithmRFC896: 对于一个TCP连接, 只要还有一个数据包的没有被确认, 就将应用发送的数据缓存下来, 直到接收到该数据包的ACK之后才允许发送新的数据.这样TCP就尽可能的发送”大”的数据包, 而不是发送多个小包, 导致效率降低. 但对于某些交互式应用如Telenet/SSH/Rlogin, 为了避免延时带来的交互延时, 通常需要关闭Nagle算法, 可以通过socket的选项参数TCP_NODELAY来关闭该算法, 从而提升交互体验.
拥塞控制
TCP的滑动窗口很好的控制了接收端与发送端的包速率, 但并没有考虑到中间网络如路由器/交换机拥塞/故障引发的网络拥堵, 为了避免网络拥塞引起网络瘫痪(congestion collapse), TCP需要对网络的拥塞信号做出反应(发生丢包/包乱序等). 总的说来, TCP的拥塞控制(congestion control)是为了:
- (1) 尽可能减少拥塞导致的网络瘫痪(如某个路由节点由于不堪重负崩溃或者卡死);
- (2) 网络使用的公平性(
faireness): TCP的目标是尽可能使每个网络的使用者都达到比较好的体验, 避免某一个发送端或者接收端过度的占用网络带宽.
在RFC5681(TCP Congestion Control)中总结了四个拥塞控制算法:
慢启动
TCP慢启动(slow start)的意思是开始发送数据时, 尽量逐步增加发送的数据量, 而不是最开始就发送一个大的数据包, 这样试探性的发送数据可以减少网络拥塞.为了实现慢启动以及拥塞避免(与慢启动配套的算法, 接下来会讲到), 需要引入两个状态变量: (1) 拥塞窗口(congestion window) cwnd; (2) 慢启动阈值(slow start threshold) ssthresh, 这个阈值用于慢启动与拥塞避免两个算法之间的切换.
慢启动算法的大致步骤如下:
- 将
cwnd设为1, 表示一个MSS大小(目前一般Linux系统都按照Google的建议将该值设为10) - 每次接收到一个ACK后,
cwnd += 1
这样收到一个ACK后,cwnd变为2,接着会发出两个MSS的数据包, ACK会变成4, 最终发送的包数量呈指数上升.等到cwnd > ssthresh, 则进入拥塞避免阶段, TCP会根据收发包的丢包重传的情况, 适当调整cwnd的值, 确保不要让网络变得过度拥堵.
拥塞避免
当cwnd > ssthresh时, TCP进入拥塞避免(congestion avoidance), 此时cwnd会进入线性调整阶段:
sshthresh的值大小一般初始化为65535(0x7ffffff)- cwnd += 1/cwnd(参考[https://tools.ietf.org/html/rfc5681]
- 每过一个RTT, 则
cwnd = cwnd + 1
当发生RTO重传时, 需要减少sshthresh的值, 同时减少cwnd的值:
sshthresh = max(FlightSize/2, 2*MSS)cwnd = 1
这样在重传之后TCP又进入了慢启动模式, 逐步增加发送数据包的速率.
快速重传与快速恢复
先来了解下快速重传(fast restransmition)与快速恢复(fast recovery)的具体含义:
- 快速重传: 在TCP接收到连续3次DACK(
duplicate ACK)后, 主动重传丢失的数据包, 而不是等到RTO超时 - 快速恢复: 当TCP完成快速重传后, 会进入拥塞避免而不是慢启动, 这样确保发送的流量在适当的拥塞之后保持稳定
一般来说, 快速重传与快速恢复是同一起实现的, 具体的流程如下:
- 如果连续收到三个DACK包, 则重传丢失的数据包
- 更新拥塞窗口以及慢启动阈值:
sshthresh = max(FlightSize/2, 2*MSS)以及cwnd = ssthresh + 3 * MSS - 后续每收到一个DACK, 将拥塞窗口加一:
cwnd = cwnd + 1 - 如果收到ACK, 则
cwnd = sshthresh, 这样TCP会再次进入拥塞控制
实际TCP针对丢包与重传的情况还有很多改善型算法, 详细可以参考RFC5681