
Claude Code(以下简称CC)是Anthropic的AI编程助手,以终端的形式与用户进行交互(Anthropic的工程师确实有点品味,让人重新回到了UNIX命令的时代,对于长期使用Mac或者Ubuntu的开发者来说,CC用起来确实得心应手)。用户通过CC可以用自然语言描述需求,发送命令,CC收到后,在它自有的代理循环中,收集上下文,分析代码库,阅读文档,并执行相关的动作,验证结果。

跟GitHub Copilot这类代码补全工具不同,CC更像个编程搭档,一个私人助手。你跟它对话,而不是等它自动补全几行代码;它会记住你的历史会话,维护上下文,帮助你快速的解决问题。理解陌生项目、写测试用例、代码重构,到需求分析、方案设计,到实现、部署,CC都能帮上忙。在很大程度上,CC帮助了Anthropic公司更高速的发展,推动了大模型在各个领域尤其是软件开发上的普及。
在这篇文章里,主要介绍下CC的安装与配置,以及使用的最佳实践。
安装与配置
环境要求
- Node.js: 18 或更高版本
- Git: 用于版本控制
- 操作系统:macOS、Linux、Windows 都行
以下安装或者操作的命令都是在
Linux环境下进行的,如果你的操作系统是macOS或Windows,可能需要进行相应的调整。
用npm全局安装:
1 | npm install -g @anthropic-ai/claude-code |
安装完成后,可以运行 claude 命令:
1 | claude --version |
如果要更新到最新版本,可以运行 npm update -g @anthropic-ai/claude-code。
首次启动
第一次运行 claude 会引导配置。如果想跳过引导,可以直接编辑用户主目录下的 ~/.claude.json(Windows 用户对应 C:\Users\<用户名>\.claude.json),加入以下内容:
1 | { |
完成初步的配置后,核心的步骤就是接入一个可用的大模型。国外模型如Anthropic的Opus/Sonnet模型,OpenAI的GPT-4模型,国内模型如智谱的GLM系列模型,月之暗面的Kimi K2模型以及DeepSeek模型,都可以接入。这里主要介绍下国内常见大模型的接入方法(国外的模型一般需要通过代理接入)。
配置国内大模型
接入大模型,需要配置两个核心的环境变量,分别是ANTHROPIC_AUTH_TOKEN和ANTHROPIC_BASE_URL,这个一般可以在大模型的官方文档中找到。
编辑 ~/.claude/settings.json:
1 | { |
下表中汇总了常见的国内大模型的接入方法,可以参考下:
| 模型 | Anthropic 兼容 API 地址 | 模型名称 | 获取 API Key |
|---|---|---|---|
| 智谱 GLM | https://open.bigmodel.cn/api/anthropic |
glm-4.6 |
智谱开放平台 |
| Kimi K2 | https://api.moonshot.cn/anthropic |
kimi-k2 |
Moonshot 控制台 |
| DeepSeek | https://api.deepseek.com/anthropic |
deepseek-chat |
DeepSeek 平台 |
说明:各家模型名称会随版本迭代而变化(如智谱已有 GLM-4.6 / GLM-5.2 等多个版本),配置时请以开放平台给出的最新模型 ID 为准。
阿里云通义千问(Qwen)目前主要提供 OpenAI 兼容接口,若要在 Claude Code 中使用,需要借助 claude-code-router 这类协议转换工具。
CC对于不同任务场景使用了不同的大模型,我们不用关心具体的模型名称,用别名就行:
| 别名 | 说明 |
|---|---|
default |
默认配置的模型 |
sonnet |
日常编码任务 |
opus |
复杂推理,如方案设计,大数据分析,生成研究报告等 |
haiku |
简单任务,速度快 |
sonnet[1m] |
100万令牌上下文 |
opusplan |
计划用 Opus,执行用 Sonnet |
可以通过 model 命令切换模型:
1 | /model sonnet |
常用命令
使用CC可以通过命令行终端进入交互模式,也可以直接在当前的终端中执行命令。
| 命令 | 功能 |
|---|---|
claude |
启动交互模式 |
claude "task" |
执行一次性任务后退出 |
claude -p "query" |
执行查询后退出 |
claude -c |
继续最近对话 |
claude -r |
恢复历史对话 |
claude commit |
智能创建 Git 提交 |
/clear |
清除对话历史 |
/help |
显示命令列表 |
使用示例
1 | # 快速修复 |
自定义斜杠命令
在 ~/.claude/commands/ 或项目的 .claude/commands/ 目录创建Markdown文件:
1 | # 全局命令 |
使用时直接输入 /optimize 或 /codereview即可执行自定义命令。
扩展能力:MCP / Subagents / Skills / Plugins
Claude Code 提供了多种扩展机制,初学时容易混淆,先简单做个区分:
- MCP(Model Context Protocol):一种标准化协议,让 Claude Code 能访问外部工具和数据源(如数据库、JIRA、Sentry)。
- Subagents(子代理):拥有独立工作空间、记忆和身份配置的专用代理,适合处理特定类型的任务(如代码审查、测试编写)。
- Skills(技能):可复用的提示词与工作流封装,模型会自主判断是否调用。
- Plugins(插件):将 Skills / Hooks / Subagents / MCP 服务打包在一起,可以一次性安装。
下面以最常用的 MCP 为例说明。
MCP 服务集成
能做什么
- 从 JIRA 读取任务并创建 PR
- 查询 Sentry 错误日志
- 从数据库读取数据
- 抓取网页内容
配置作用域
| 作用域 | 配置位置 | 适用场景 |
|---|---|---|
| Local | ~/.claude.json |
个人实验、敏感凭证 |
| Project | .mcp.json |
团队共享、CI/CD |
| User | ~/.claude.json |
个人通用配置 |
示例:集成 Sentry
1 | claude mcp add --transport http sentry https://mcp.sentry.dev/mcp |
然后在对话中输入 /mcp 进行认证,之后就能查询错误信息了。
更多 MCP 服务见 MCP Registry。
记忆系统
Claude Code 主要有两级记忆文件:
| 类型 | 文件路径 | 用途 |
|---|---|---|
| 用户记忆 | ~/.claude/CLAUDE.md |
个人编码偏好,所有项目共享 |
| 项目记忆 | ./CLAUDE.md |
团队规范,随项目提交到仓库 |
早期版本还存在
./CLAUDE.local.md(用于不提交到仓库的个人项目配置),新版已逐步被~/.claude/settings.json的项目级配置取代,不再推荐使用。
用户记忆示例
~/.claude/CLAUDE.md:
1 | # 我的编码偏好 |
项目记忆示例
项目根目录 CLAUDE.md:
1 |
|
更多关于Claude Code的工作原理,可以参考官方的文档:how-claude-code-works。
最佳实践
要想用好CC,核心是记住一个关键的约束条件:CC的工作依赖于模型的上下文窗口(context window),在对话的过程中,上下文窗口会快速占用(对话内容,读取的文件,命令输出等),因此模型的性能也会下降,容易出现指令遵循下降、出现幻觉等问题。因此,要充分发挥CC的能力,需要充分利用上下文窗口,在使用过程中尽可能减少对上下文窗口的占用,减少错误发生的概率。
清晰描述需求
无论是实现某个功能,进行功能开发,还是修复某个代码BUG,都需要尽可能清晰的将问题的描述和需求清晰地表述给Claude Code,比如:
1 | # 不太好 |
比如要访问的某个具体的文件或者实现功能的具体约束,都要尽可能具体的说出来。对于每个任务,给Claude Code一个明确的验收标准,可以用来验收对应的任务是否正常完成。
| 描述策略 | 优化前 | 优化后 |
|---|---|---|
| 限定任务的范围:指定具体文件,什么场景,以及测试的偏好 | 为foo.py添加测试 | 为foo.py添加测试,覆盖用户登录的边界场景,避免使用Mocks |
指定数据源:指示Claude Code使用具体的数据源来回答问题 |
为什么ExecutionFactory有一个如何奇怪的API |
查看下ExecutionFactory的提交记录,总结下其API的来源 |
引用现有的模式:指示Claude Code使用已有的编码模式 |
添加一个日历的组件 | 先查看首页现有组件的实现逻辑,理清统一开发规范;以现有的UserInfoCard.vue 为参考范例,遵循相同规范开发全新日历组件,支持选择月份、翻页切换年份;仅使用项目已有依赖库,从零实现,不引入新第三方库 |
| 描述具体问题症状:提供BUG的具体症状描述,可能发生的位置,以及可能修复的方式 | 修复登录的BUG | 户反馈会话超时后登录失败,请核查 src/auth 目录下鉴权流程,重点排查令牌刷新逻辑;先编写可复现问题的失败测试用例,再修复该缺陷 |
方案先行,后编码
对于一些不确定的问题或者任务,在要求Claude Code编码之前,最好的办法是先让其基于当前的代码输出一个详细的实施方案,然后再进行编码。这样可以避免很多错误。比如我要修复某个问题,可以让Claude Code进入plan模式,等其完成梳理后,再执行bug修复,最终进行代码提交。
比如将复杂任务分拆,分步骤做:
1 | > 第一步:分析当前代码结构 |
可以使用
/plan命令进入plan模式,或者通过shift + tab在不同模式之间进行自动切换。
善用CLAUDE.md
Claude Code中的CLAUDE.md分为不同的层级:
- 项目根目录的
CLAUDE.md文件,用来描述整个项目的目标、需求和规范,在会话期间会持续占用上下文窗口 - 在项目子目录的
CLAUDE.md文件,在Claude Code进入子目录时,会自动加载到模型的上下文中,退出该目录后,会自动从上下文中移除
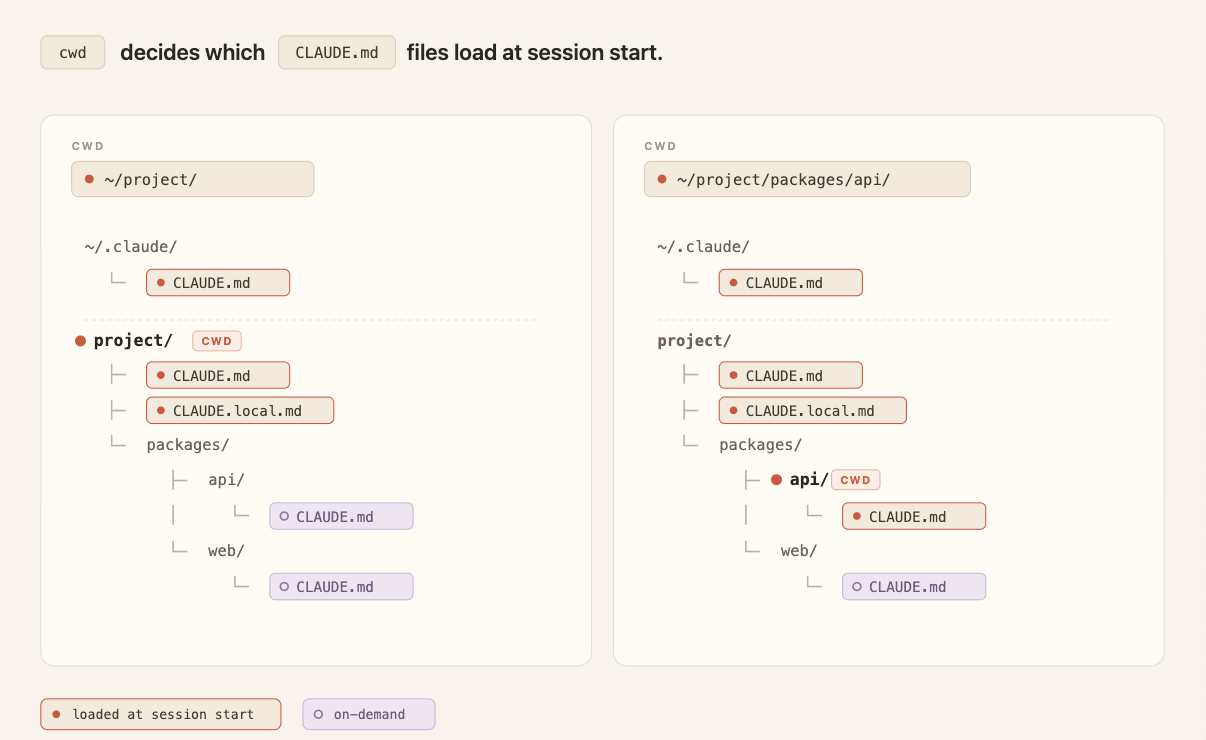
因此,为了减少Token的消耗,降低CLAUDE.md对上下文的占用,尽可能保持CLAUDE.md简单清晰(最好不要超过200行),只是提供一个项目概览与相关信息的索引,将很多规则与重复性的内容放到rules或者skills目录中。
结语
AI大模型无疑是新的工业革命生产力的核心,如果你对大模型的能力还有疑虑,那很可能是用的还不够多,不够深入。随着Agent系统的发展,AI的能力正在从代码开发扩展的其他领域,不再简单是一个生产工具,而是一个真正意义上的协作者(CoWorker)。未来,随着大模型能力的进一步提升,组织的形态与工作流都会被AI改变,重构。Claude Code是这个时代的生产力工具,如何用好它,可能是现代数字游民必要的生存技能,也是个人与组织竞争力的体现。