
对于任务调度器来说,在发生调度时需要决定选择某个进程调度到哪个CPU执行,同时还需要基于系统当前的负载,实时的调整CPU运行的频率。Linux进程调度器为了适配各种不同场景的设备,如服务器,嵌入式设备,通常需要在多个性能目标上进行权衡取舍:
- 需要确保调度尽可能公平,保证每个任务都有机会得到执行
- 快速响应用户请求,比如对于交互式的用户任务,需要降低调度延迟,快速调度任务执行
- 实现更高的系统吞吐量,可以满足更多的任务并发执行
- 同时尽可能降低系统功耗,在系统空闲或者负载降低时尽可能减小工作频率,减少能耗
通常来说,这些目标是相互冲突的,在公平调度器(CFS(Complete Fair Scheduler))出来之前,之前的调度器并没有很好的解决这些问题。最开始Linux内核采用的是O(n)调度器,每次执行任务调度时会扫描就绪队列上的所有进程,计算进程的优先级,再从中选择一个最高优先级的任务执行,O(n)调度器的调度时间随着系统进程数量增加呈现线性增长,因此很难以进行扩展。为了解决该问题,2002年内核中引入O(1)调度器,其基本思想是,将进程的优先级分为动态优先级与静态优先级,静态优先级用于计算每个任务可运行的时间片长度,动态优先级在调度时用到,每次调度的都会选择动态优先级最高的任务运行。O(1)调度器采用了一个动态优先级数组来存放可运行的任务,因此可以在O(1)时间内选择一个最优的任务。
O(1)调度器虽然解决了调度延迟的问题,但无法准确的判断系统中交互式与批处理两种类似的任务,从而导致交互延迟;O(1)调度器发明人Ingo Molnar在Con Kolivas发明的调度器RSDL(The Rotating Staircase Deadline Scheduler)基础上实现了一个全新的调度器CFS: CFS换了一种思路,不再单纯通过优先级来选择执行的任务,而是通过计算进程消耗的CPU时间来决定哪个任务可以被调度,它会根据系统的任务优先级来计算出每个任务所需要的虚拟时间(vruntime),调度时只需要选择虚拟时间(vruntime)最小的任务执行即可。
CFS虽然做到了足够的公平,但未考虑到任务的延迟lag,比如某个任务预期需要执行20ms,而实际上只拿到了10ms的CPU时间,这个差值认为是一个任务的延迟,在这种情况下按照CFS的调度策略执行,在极端情况下可能会导致该任务无法立即调度,从而导致响应的延迟。为了减少这种任务的调度延迟,新的调度器(EEVDF(Earlist Eligible Virtual Deadline First))基于该延迟计算出每个任务的截止时间(deadline),在实际调度时会选择截止时间最小的任务执行,以此改善任务调度的延迟。
CFS在SMP这种对称的系统中可以很好的发挥作用,因为调度时无需考虑单个CPU的差异,但如果处理如AMP(非对称系统), HMP(异构系统)等更复杂的情况就显得力不从心。在3.18之前的内核版本中,CFS调度器都是根据每个运行队列上的负载来执行负载跟踪(PRLT,Per Runqueue Load Tracking),PRLT有个比较明显的缺点,无法准确的知道每个进程对整体负载的贡献,因此难以准确对任务的负载的轻重做出判断,在ARM大小核的框架下,可能导致任务错配,比如重任务放到了小核上执行,而轻任务则放到了大核上,从而降低了系统的运行效率。Linux内核从3.18版本开始,引入了PELT(Per-Entity Load Tracking),以便更准确的跟踪系统的负载;高通针对PELT响应慢的问题,提出了WALT(Window Assisted Load Tracking)算法,目前所有高通的平台都默认使用WALT来跟踪负载。
这篇文章,我们主要介绍下负载跟踪算法PELT、WALT的实现原理以及对两个算法进行对比。
本文基于Linux内核版本5.4分析
PELT
PELT(Per-Entity Load Tracking)中的Entity对应一个调度实体,可以是一个进程,也可以是一个cgroup中的所有进程。为了跟踪每个Entity的负载,系统时间(物理时间,非虚拟调度时间)被分成1024us(1ms)的时间序列,在每一个1024us的周期内,一个调度实体对系统的负载贡献可以根据该实体处于runnable状态(正在执行或者等待CPU调度执行)的时间来计算:如果该周期内,runnable的时间为x,相应的该实体对系统负载的贡献为x/1024。但如果要考虑更长时间(超过1ms)的负载状态,就需要将多个周期内的负载进行加权处理(离当前越近对当前系统负载贡献越小)得到系统的整体负载。假定$L_i$表示负载计算周期$p_i$的调度实体负载,那么该实体对系统负载的贡献可以表达为(指数权重滑动平均,EWMA):
$$ L = L_0 + L_1y + L_2 * y^2 + L_3 * y^3 + … = \sum_{i=1}^n L_iy^i $$
这里参数y是衰减权重值,一般按照$y_32=0.5, y≈0.9786$得到,表示调度实体经过32个计算周期后,其对当前系统负载的贡献值为0.5;而当前时刻的负载对系统负载的贡献权重为1;类似的,我们向前滚动一个计算周期(1ms),则可以得到该任务新的负载贡献值:
$$ L = L_0’ + y (L_0 + L_1y + L_2 * y^2 + L_3 * y^3 + …) \
= L_0’ + L_0 * y + L_1*y^2 + L_2 * y^3 + L_3 * y^4 + …) $$
可以看到当前时间负载就是该调度实体当前的负载,再加上前一个周期的负载乘以衰减系数y即可;因此,想要计算出当前负载,一般只需要计算出$val*y^n$即可,我们已知$y^n = \frac{1}{2}$,可以将$y^n$的计算转换为如下:
$$ y^n = \frac{1}{(2)^\frac{n}{p}} * y^{n%p} $$
这里的p表示负载计算的衰减周期,一般为32ms;实际上,我们只需要把0 < n <= 32这些情况的数据计算出来,对于n > 32的情况,只需要通过如下公司计算出来即可,比如计算n=35的情况:
$$ y^{35} = \frac{1}{(2)^\frac{35}{32}} * y^{35%32} = \frac{1}{2} * y^3 $$
为了避免浮点运算,提高计算效率,内核会提前计算好0 < n <= 32的情况,将$y^n*2^32$的值计算好,保存到一个runnable_avg_yN_inv数组里,这样实际计算的时候只需要查表即可得到$y^n$的值;具体计算的代码可以参考Documentation/scheduler/sched-pelt.c:
$$ runnable_avg_yN_inv[i] = (2^{32} - 1) * y^i $$
基于该预计算的数据,内核在计算调度任务的负载时,直接通过如下函数decay_load就可以得到对应时刻负载的衰减权重系数:
1 |
|
实际计算当前时刻的负载要更麻烦些,具体可以参考内核代码sched/pelt.c中的函数accumulate_sum;为了跟踪系统负载,内核在任务结构体struct task_struct中增加了一个struct sched_avg的结构体,用以保存系统负载相关的状态:
last_update_time: 上一次系统负载更新的时间点,基于与上次更新的时间差,我们可以计算对应的load_avg/util_avg的值load_sum/runnable_load_sum/util_sum:根据上述中的权重衰减级数得到的系统负载值,load_sum是衰减周期内所有负载的总和,包括了running/runnable两种状态的时间;util_sum仅包含running时间。对于普通任务来说,runnable_load_sum等于util_sum,对于一个分组调度实体来说,runnable_load_sum是所有该分组任务的running+runnable时间的总和period_contrib: 计算中间值,用于保存负载计算时时间窗口的临时值load_avg/runnable_avg/util_avg: 根据*_sum计算得到的平均值util_est: 任务阻塞后,其负载会不断衰减。如果一个重载任务阻塞太长时间,根据标准PELT计算出来的负载会非常小,当该任务被唤醒时,由于负载较小会让调度器做出错误的判断。因此引入了这个成员,记录阻塞之前的负载均值load_avg信息
1 |
|
Linux内核调度器在执行任务调度的时候或者内核时钟中断来时,会实时更新当前系统的负载,比如在任务入队(enqueue_task_fair)、出队(dequeue_task_fair)或者切换不同的cgroup分组(task_change_group_fair)的时候会主动更新当前负载;以任务入队函数enqueue_entity为例,在更新完任务的优先级相关的时间片信息后,会通过update_load_avg更新系统负载。
1 |
|
函数update_load_avg主要作用是更新系统的负载状态,包括更新当前调度任务的负载,对应任务队列的负载,同时需要更新任务所在的分组的负载状态:
__update_load_avg_se: 更新当前调度实体的负载信息update_cfs_rq_load_avg: 更新调度实体对应的任务队列上的负载propagate_entity_load_avg: 将调度实体的负载信息在控制分组内进行传递cfs_rq_util_change: 如果负载有更新,需要通知系统调频模块选择一个适当的CPU频率
1 |
|
WALT
WALT(Window Assisted Load Tracking)一种基于时间窗口(一般默认为16ms,高通的代码里会根据系统时钟中断频率HZ来调整窗口大小)的负载跟踪算法,是高通针对手机移动平台提出的一种负载跟踪方案。其基本思想是,基于一个固定的时间窗口来计算任务负载,同时会考虑过去几个窗口内(默认是计算5个窗口内的负载均值)的负载情况,实际计算时会取当前负载与历史负载均值的最大值作为任务的当前负载。
WALT算法在当前struct task_struct中嵌入了一个struct walt_task_struct用于保存负载相关的信息,包括当前窗口的负载,历史负载,以及CPU能力归一化后的负载:
mark_start: 任务开始执行的时间标记sum: 当前窗口任务总的运行时间(包括运行时间和等待时间,做了频率缩放)sum_history: 上一个窗口任务总的运行时间(不包括休眠时间)demand: 上一个窗口最大的任务负载,用于调节CPU工作频率curr_window_cpu: 当前窗口任务在各个CPU上的运行时间prev_window_cpu: 上一个窗口任务在各个CPU上的运行时间pred_demand: 当前窗口预测的任务负载(用于EAS功耗感知调度)demand_scaled: 当前窗口任务的归一化后负载(缩放到了1024)
1 |
|
WALT负载计算是根据系统的事件来触发的,比如系统时间中断,任务状态变化(任务创建、唤醒、切换等),负载均衡,中断等都会重新计算任务的负载信息,比如执行调度函数_schedule时,会调用walt_update_task_ravg更新任务负载信息:
- 首先调用
update_window_start函数更新任务窗口开始时间 update_task_rq_cpu_cycles更新任务队列的CPU运行的周期update_task_demand更新任务的负载信息,这个是WALT算法的关键函数update_cpu_busy_time更新CPU在该窗口内的运行时间信息update_task_pred_demand更新任务的预测负载信息run_walt_irq_work触发一个软中断,用于更新当前CPU的工作频率
1 |
|
真正更新任务负载的函数是update_task_demand。负载的计算主要有三种不同的情况:
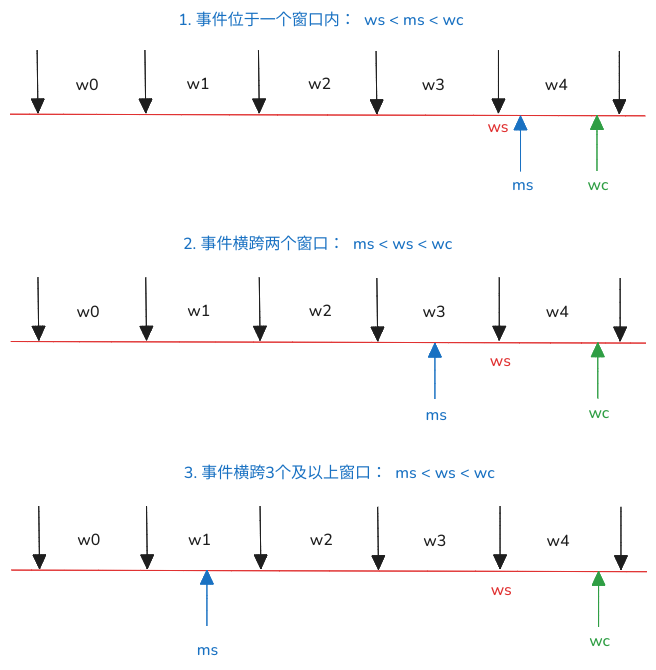
- 如果系统事件在当前窗口(
ws < ms <wc)内发生,那么只需要更新当前窗口的任务负载 - 如果系统事件横跨了两个窗口(
ms < ws < wc),任务开始的时间在上一个窗口,那么需要更新当前窗口的任务负载和上一个窗口的任务负载 - 如果系统事件横跨多个窗口(
ms < ws < wc)),即任务开始的时间在之前的某个窗口,那么需要更新所有的历史窗口的任务负载
任务计算运行时间的方式就是根据ws和ms的差值缩放到1024(CPU的最大默认能力),基于任务的运行时间,WALT选择历史窗口中平均负载值与当前任务负载中较大的一个作为真正的负载,缩放后得到demand_scaled作为系统调频、任务放置等决策依据,具体可以参考函数update_history的实现:
$$ delta = (ws - ms) * cur_cpu_freq/max_cpu_freq * cpu_capacity / 1024 // 任务缩放后的执行时间 $$
1 |
|
最后系统调频时,基于WALT计算出来的负载,可以以此调整CPU运行的频率,具体可以参考cpufreq_schedutil.c:
1 |
|
PELT与WALT的对比
PELT是ARM公司开发的一种负载跟踪算法,基于滑动平均的方式预测任务负载,但由于其缺乏对大小核(Big.Little)架构的支持,加上其负载衰减慢,因此并不合适手机等终端设备这种负载突发、变化频繁的系统,WALT针对上述的缺点做了改建优化,总结来说,两者的区别如下:
PELT负载跟踪只考虑到了SMP这种架构,对于当前手机芯片HMP这种异构体系并不合适;而且,PELT只是考虑到了CFS调度类的负载跟踪,并没有考虑到系统其他调度类,如RT/DEADLINE等,因此缺乏对系统负载的全局性考虑。- 考虑到移动平台大小核(
Big.Little)的体系架构,会将负载基于CPU能力与频率进行归一化处理,从而更准确的判断任务负载与CPU能力之间的匹配 - 从调度、调频的延迟来看,由于
PLET考虑了更长的时间周期,因此无法快速响应负载,对于像Android这样的移动平台来说,可能会出现系统响应变慢;WALT能更快速的响应突发的负载,但相对来说可能会带来更多的能耗
Linaro的官网上有一个文档对PLET与WALT的比较进行了详细的分析,可以参考下PELT vs Window tracking
and EAS on SMP multi-cluster。
参考资料
- https://blog.csdn.net/lizhijun_buaa/article/details/135954017
- https://www.cnblogs.com/lingjiajun/p/12317090.html
- https://lwn.net/Articles/531853/
- http://www.wowotech.net/process_management/PELT.html
- http://www.wowotech.net/tag/pelt
- https://blog.csdn.net/feelabclihu/article/details/108414156
- https://www.anandtech.com/show/12620/improving-the-exynos-9810-galaxy-s9-part-2/2
- https://lwn.net/Articles/925371/
- https://android.googlesource.com/kernel/msm/+/android-msm-bullhead-3.10-marshmallow-dr/Documentation/scheduler/sched-hmp.txt