
VLAN(Virtual Local-Area-Network)虚拟局域网,用于将一个物理局域网(LAN)在逻辑上分割为多个独立虚拟的广播域;每个VLAN都对应一个广播域,可以直接通讯,而不同VLAN的主机则无法直接互通,这样广播报文就限定在一个固定的VLAN内。VLAN工作在网络协议栈的数据链路层(L2),通过在网络数据报文中增加一个额外的VLAN标签,从而让同一个物理局域网的流量可以像多个物理局域网一样分隔开来;另外,我们也可以利用VLAN中的优先级标签来保证局域网中的高优先级流量可以更低延迟的进行传输,从而提升整个网络的传输质量。这篇文章,主要从两个方面介绍下VLAN:
- 首先介绍下如何创建、配置
VLAN - 其次基于数据报文分析下
VLAN是如何在Linux内核中实现的
配置VLAN
在实际的应用中,我们可以基于一个物理网卡或者桥接口(bridge)来创建VLAN,Linux下可以通过ip link命令执行VLAN的创建:
1 |
|
这里我们基于一个物理网口eth0配置了一个ID为100的VLAN网口,其对应的网口名为vlan100(可以自定义);为了让VLAN的网口开始工作,我们需要像配置一个物理网卡一样,给VLAN网口配置IP地址,并设置为运行状态(UP):
1 |
|
通过ifconfig vlan100我们可以查看到配置好的VLAN网口状态:
1 |
|
VLAN的实现原理
交换机要识别不同VLAN的数据报文,需要在原有以太网的数据帧中增加一个4 bytes的VLAN标签,用于识别VLAN信息;从下图可以看到,VLAN帧在原有的以太网帧中增加了一个tag标签数据,其中2个字节用于表示对应的上层协议类型;另外2个字节包含3个部分的信息:
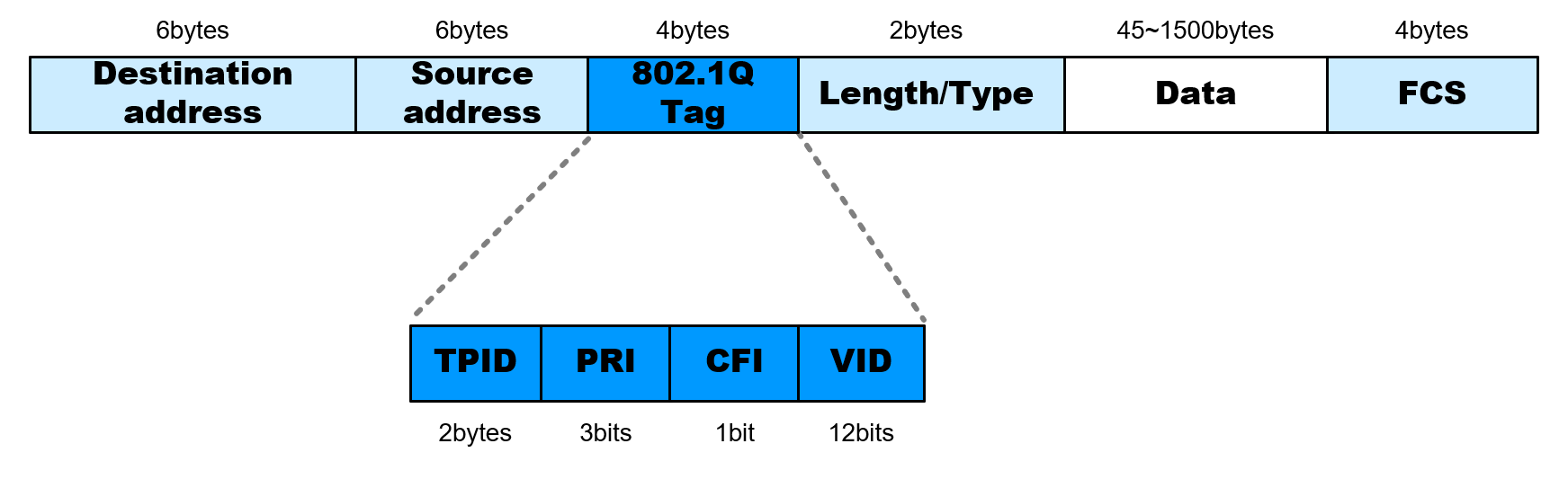
TPID(Tag Protocol Identifier, 2bytes): 基于IEEE 802.1Q标准,一般设定为0x8100PRI(Priority, 3bits): 0~7,用于表示流量的优先级CFI(Canonical Format Indiciator, 1bit)/DEI(Drop Eligible Indicator, 1bit):CFI用于表示MAC地址是否以标准的形式表示,如果该值是0表示是标准形式(低位先传输);为1则表示非标准形式(高位先传输);而DEI配合优先级状态PRI,在网络拥塞时选择丢弃某些报文。实际应用中,这两个标志位可以自行选择使用VID(VLAN Identifier, 12bits): 大小范围为0-4095,用于表示数据报文对应的VLAN,其中0/4095为保留的VLAN值,实际可用的值在1-4094之间
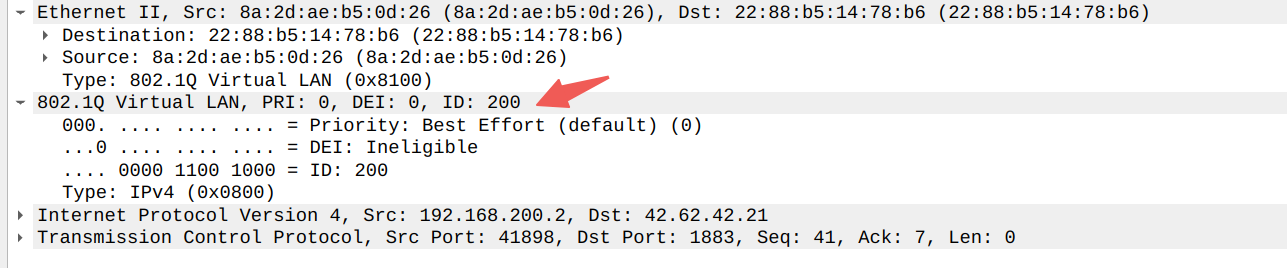
以实际抓取tcpdump报文来看看具体的VLAN数据是如何组成的,报文的开始是由目标与源MAC地址,共12个字节;接着是4个字节的VLAN标签数据:
Type(0x8100): 对应的是TPID,可以看到该报文是基于IEEE 802.1QPriority(0): 对应PRI,默认值是0DEI(0): 丢弃优先指示,不会丢弃报文ID(200):VLAN ID为200
接下来,我们还是从Linux的源码的角度来看看VLAN的大致实现原理。
Linux如何实现VLAN
从文章开头部分,我们知道,配置VLAN是通过的ip link命令来实现的,Linux下的ip相关指令都在iproute的开源库中实现的,我们找到对应的源代码iproute2/ip/iplink.c,可以看到,实际ip link命令最后都是通过iplink_modify函数发送一个netlink的套接字消息给内核,用于建立新的VLAN网口:
1 |
|
在Linux内核中,netlink相关的内核实现都在net/core/rtlink.c中,内核在初始化rtnetlink_init的时候,会注册很多netlink相关的指令处理函数,这样应用可以通过netlink套接字来向内核发送指令,实现诸如路由配置、VLAN创建、ARP配置等功能:
本文的分析基于Linux V5.10版本
1 |
|
我们重点来看看创建link相关的实现。rtnl_newlink的核心功能都通过__rtnl_newlink实现;函数__rtnl_newlink主要做了如下几个事情:
- 首先,通过
nlmsg_parse_deprecated解析netlink的消息数据,将其转换成一个struct nlattr数据 - 接着,调用
validate_linkmsg验证下各个数据类型是否符合实际的要求,比如IP地址长度是否超限 - 通过
IFLA_LINKINFO解析link相关的信息,用于获取link的类型IFLA_INFO_KIND - 调用
rtnl_create_link创建一个VLAN的网卡设备 - 通过
struct rtnl_link_ops中的newlink完成最终的VLAN的链路创建如果对netlink数据传输有兴趣的,可以通过strace来跟踪具体的系统调用状态
1 |
|
结构体struct rtnl_link_ops是一个用于配置网卡的接口,内核的其他模块在初始化时会通过rtnl_link_register注册一个对象,这样用户就可以通过统一的netlink来实现各种类型的网口的配置了。
1 |
|
VLAN的内核模块(net/8201q/vlan_netlink.c)在初始化时,会注册对应的struct rtnl_link_ops vlan_link_ops对象:
1 |
|
也就是说,创建VLAN网口的实际就是调用vlan_setup与vlan_newlink等函数进行网口的设置与注册,这样对系统来说,VLAN网口跟其他的物理网卡没有本质上的区别,只要路由到这里的数据都会添加上VLAN的标签,然后通过真正的物理网卡发送出去;而从其他节点发送过来同一VLAN标签的数据都会发送给该网口进行处理,如果对内核的具体实现感兴趣可以参考源代码目录net/8201q。
1 |
|
最后,我们来看一看网络数据从物理设备过来之后,VLAN网口是如何进行处理的?网络数据从物理网卡过来之后,通过内核的软中断线程进行统一处理,最终会调用核心函数__netif_receive_skb_core对网络数据报文进行处理(了解网络数据接收流程,可以参考从NAPI说一说Linux内核数据的接收流程);在这个函数中,会检查以太网帧的协议类型是否为VLAN,如果带有VLAN标签,则首先会解析该标签,然后通过vlan_do_receive进行处理:
1 |
|
函数vlan_do_receive(net/8021q/vlan_core.c)首先通过协议类型与VLAN ID找到对应的VLAN网口,然后将其设置到对应的struct sk_buff设备上;接着会调用__vlan_hwaccel_clear_tag清除VLAN的标签,并更新网卡设备的网络数据统计:
1 |
|
总结
虚拟局域网VLAN可以不用更改现有的物理网络拓扑结构,实现网络的虚拟分割,从而方便的实现网络流量的隔离;VLAN可以用来划分公司的内部网络,也可以用来对局域网的流量进行优先级控制。但VLAN最多只能有4096个划分,比较适合小型的局域网络,为了解决VLAN的这一问题,后来又出现了VXLAN(Virtual Extensible LAN)可以支持更大型的网络扩展与分割。
参考资料
- https://dev.jmgilman.com/networking/concepts/switching/vlan/
- https://wiki.archlinux.org/title/VLAN
- https://www.redhat.com/en/blog/vlans-configuration
- https://info.support.huawei.com/info-finder/encyclopedia/zh/VLAN.html
- https://support.huawei.com/enterprise/en/doc/EDOC1100174721/75653f56/vlan-frame-format