Android从9.0版本开始全面支持eBPF(extended Berkeley Packet Filters), 其主要用在流量统计上, 也可以用来监控CPU/IO/内存等模块的状态.简单来说, eBPF可以与内核的kprobe/tracepoints/skfilter等模块相结合, 将eBPF的函数hook到内核事件从而监控相应的系统状态.
Android为eBPF提供了许多封装的库, 并提供了eBPF加载器bpfloader:
bpfloader: 位于/system/bpf/bpfloader, 系统启动时负责加载位于/system/etc/bpf 中的eBPF目标文件libbpf_android: 位于/system/bpf/libbpf_android提供创建bpf容器/加载bpf目标文件的接口libbpf: 位于/external/bcc, 封装了bpf的系统调用, 提供如attach/dettach程序的接口libnetdbpf: 位于/system/netd/libnetdbpf, 实现了netd流量统计功能的函数
目前在Android(Q)上有两处eBPF的代码: 一个是/system/netd/bpf_progs/netd.c, 主要是用于流量统计;一个是/system/bpfprogs/time_in_state.c用于监控CPU运行频率以及上下文切换的耗时.
接下来我们就从三个部分来深入理解下Android是如何利用eBPF的:
eBPF程序与目标文件格式
Android eBPF加载与执行流程
Android如何基于eBPF实现流量统计
有关BPF的介绍可以参考之前的文章BPF与eBPF
eBPF程序与目标文件的格式 在Android中, 一个eBPF的c程序格式通常如下, 总的说来分为三个部分:
通过DEFINE_BPF_MAP定义BPF数据容器的类型以及访问接口
声明代码段, 比如SEC("cgroupsock/inet/create")
声明BPF段的证书类型, 一般是GPL或者跟GPL兼容的证书类型(如果要使用内核的某些辅助函数,如bpf_trace_printk的话一定要使用GPL证书,否则无正常加载)
看内核代码, 对于大部分的BPF容器类型可以是GPL的, 也可以是其他证书, 但对于stackmap.c则要求只能是GPL的.但如果要使用某些函数,如bpf_perf_event_read/bpf_trace_printk则要求使用GPL,否则会验证不过,无法加载,具体可以参考bpf_trace.c, 有关辅助函数可以参考bpf-helpers
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <bpf_helpers.h> DEFINE_BPF_MAP(name_of_my_map, ARRAY, int , uint32_t , 10 ); SEC("PROGTYPE/PROGNAME" ) int PROGFUNC (..args..) { <body-of-code ... read or write to MY_MAPNAME ... do other things > } char _license[] SEC("license" ) = "GPL" ;
代码中PROGFUNC定义了一个函数, 编译后会生成一个PROGTYPE/PROGNAME的段(section), 其中PROGTYPE是eBPF代码类型, (对Android来说)必须是下表中的名字:
事件类型
BPF代码类型
说明
kprobe
BPF_PROG_TYPE_KPROBE
将ePBF函数hook到kprope上以探测内核事件, PROGNAME必须是内核中被kprobe监控的函数名
tracepoint
BPF_PROG_TYPE_TRACEPOINT
将eBPF函数hook到tracepoint事件上, PROGNAME必须是SUBSYSTEM/EVENT的格式, 例如用于监控上下文切换的段可以写成SEC(tracepoint/sched/sched_switch, 具体可以参考/sys/kernel/debug/tracing/events`下面各个系统事件名
skfilter
BPF_PROG_TYPE_SOCKET_FILTER
将eBPF函数当作一个netfilter模块执行, 参考内核代码xt_bpf.c
schedcls
BPF_PROG_TYPE_SCHED_CLS
将eBPF函数当作一个网络数据包的分类器(classifier), 参考内核代码cls_bpf.c
cgroupskb/cgroupsock
BPF_PROG_TYPE_CGROUP_SKB/BPF_PROG_TYPE_CGROUP_SOCK
每当指定的cgroup上有数据传输(SKB); 创建AF_INET/AF_INET6的socket(SOCK)时就执行eBPF函数 ,参考bpf-cgroup.h /bpf/cgroup.c
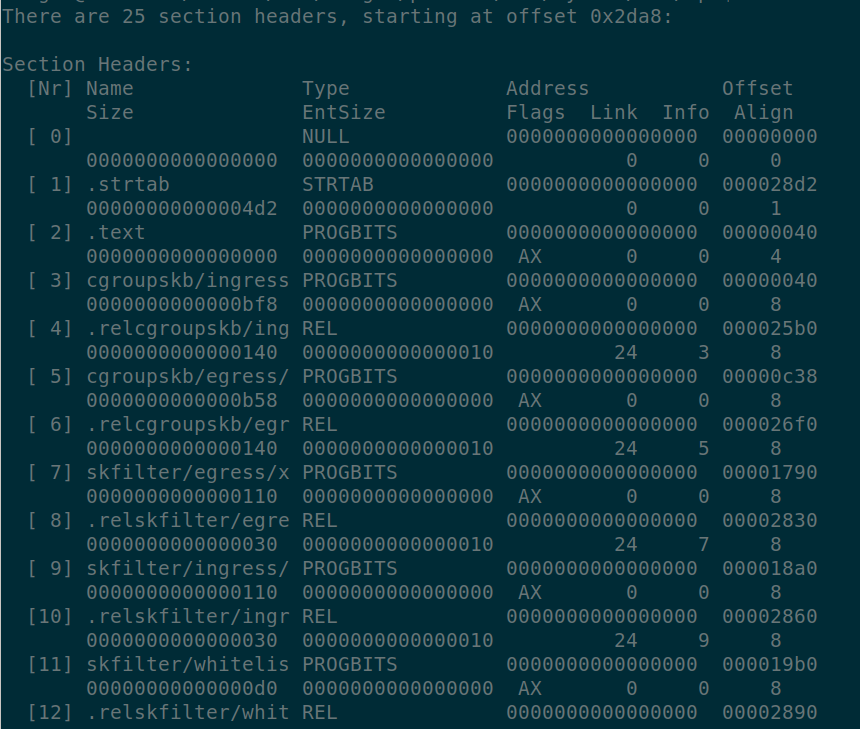
每个eBPF c语言程序都会通过LLVM编译成ELF(Executable-Link Formatreadelf/objdump工具来查看ELF文件. 比如利用readelf -S netd.o查看netd.o的段头信息, 从这里可以看到netd.c中定义的各个段:
Android中eBPF加载流程 在系统启动阶段, Android会把位于/system/etc/bpf/的eBPF目标文件通过bpfloader这个服务加载到内核:
1 2 3 4 5 6 7 8 9 10 11 12 service bpfloader /system/bin/bpfloader class main capabilities SYS_ADMIN # Set RLIMIT_MEMLOCK to 64MB for bpfloader # Actually only 8MB is needed , but since bpfloader runs as root , it shares # the global rlimit . Once bpfloader is running as its own user in the # future , it will have dedicated rlimit to itself and this can be 8MB . rlimit memlock 67108864 67108864 oneshot
进入BpfLoader.cpp看下main函数, 实际是调用loadAllElfObjects加载各个ELF文件: 读取/system/etc/bpf/下面所有.o结束的文件, 然后加载到内核.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #define BPF_PROG_PATH "/system/etc/bpf/" void loadAllElfObjects (void ) { DIR* dir; struct dirent * ent ; if ((dir = opendir(BPF_PROG_PATH)) != NULL ) { while ((ent = readdir(dir)) != NULL ) { string s = ent->d_name; if (!EndsWith(s, ".o" )) continue ; string progPath = BPF_PROG_PATH + s; int ret = android::bpf::loadProg(progPath.c_str()); ALOGI("Attempted load object: %s, ret: %s" , progPath.c_str(), std ::strerror(-ret)); } closedir(dir); } }
函数loadProg根据eBPF目标文件中的段创建容器类型, 并加载代码到内核:
首先检查是否存在证书的段(section)
readCodeSections:读取ELF文件中段信息, 生成代码段CodeSection的列表createMaps: 根据ELF目标文件中的maps段信息创建对应的容器对象applyMapRelo: 看代码应该是对BPF中的指令进行重定位(如何进行重定位?)loadCodeSections: 加载目标文件到内核, 并将加载后的fd固定到特定的路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 int loadProg (const char * elfPath) { vector <char > license; vector <codeSection> cs; vector <int > mapFds; int ret; ifstream elfFile (elfPath, ios::in | ios::binary) ; if (!elfFile.is_open()) return -1 ; ret = readSectionByName("license" , elfFile, license); if (ret) { ALOGE("Couldn't find license in %s\n" , elfPath); return ret; } else { ALOGD("Loading ELF object %s with license %s\n" , elfPath, (char *)license.data()); } ret = readCodeSections(elfFile, cs); if (ret) { ALOGE("Couldn't read all code sections in %s\n" , elfPath); return ret; } if (0 ) dumpAllCs(cs); ret = createMaps(elfPath, elfFile, mapFds); if (ret) { ALOGE("Failed to create maps: (ret=%d) in %s\n" , ret, elfPath); return ret; } for (int i = 0 ; i < (int )mapFds.size(); i++) ALOGD("map_fd found at %d is %d in %s\n" , i, mapFds[i], elfPath); applyMapRelo(elfFile, mapFds, cs); ret = loadCodeSections(elfPath, cs, string (license.data())); if (ret) ALOGE("Failed to load programs, loadCodeSections ret=%d\n" , ret); return ret; }
下面就分别来看下其中的几个关键步骤.
生成代码段,创建map 函数readCodeSections读取ELF目标文件中的段头信息, 获取到每个BPF段的代码类型, 常见的有BPF_PROG_TYPE_KPROBE, BPF_PROG_TYPE_SOCKET_FILTER等(见上述表中的说明). 接着查看该段是否需要进行重定位.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 static int readCodeSections (ifstream& elfFile, vector <codeSection>& cs) { vector <Elf64_Shdr> shTable; int entries, ret = 0 ; ret = readSectionHeadersAll(elfFile, shTable); if (ret) return ret; entries = shTable.size(); for (int i = 0 ; i < entries; i++) { string name; codeSection cs_temp; cs_temp.type = BPF_PROG_TYPE_UNSPEC; ret = getSymName(elfFile, shTable[i].sh_name, name); if (ret) return ret; enum bpf_prog_type ptype = if (ptype != BPF_PROG_TYPE_UNSPEC) { deslash(name); cs_temp.type = ptype; cs_temp.name = name; ret = readSectionByIdx(elfFile, i, cs_temp.data); if (ret) return ret; ALOGD("Loaded code section %d (%s)\n" , i, name.c_str()); } if (cs_temp.data.size() > 0 && i < entries) { ret = getSymName(elfFile, shTable[i + 1 ].sh_name, name); if (ret) return ret; if (isRelSection(cs_temp, name)) { ret = readSectionByIdx(elfFile, i + 1 , cs_temp.rel_data); if (ret) return ret; ALOGD("Loaded relo section %d (%s)\n" , i, name.c_str()); } } if (cs_temp.data.size() > 0 ) { cs.push_back(cs_temp); ALOGD("Adding section %d to cs list\n" , i); } } return 0 ; }
接着根据CodeSection列表创建内核的map对象(用于保存内核事件结果, 常见的有arraymap, hashmap等几种类型):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 static int createMaps (const char * elfPath, ifstream& elfFile, vector <int >& mapFds) { int ret, fd; vector <char > mdData; vector <struct bpf_map_def > vector <string > mapNames; string fname = pathToFilename(string (elfPath), true ); ret = readSectionByName("maps" , elfFile, mdData); if (ret) return ret; md.resize(mdData.size() / sizeof (struct bpf_map_def)); memcpy (md.data(), mdData.data(), mdData.size()); ret = getMapNames(elfFile, mapNames); if (ret) return ret; mapFds.resize(mapNames.size()); for (int i = 0 ; i < (int )mapNames.size(); i++) { string mapPinLoc; bool reuse = false ; mapPinLoc = string (BPF_FS_PATH) + "map_" + fname + "_" + string (mapNames[i]); if (access(mapPinLoc.c_str(), F_OK) == 0 ) { fd = bpf_obj_get(mapPinLoc.c_str()); ALOGD("bpf_create_map reusing map %s, ret: %d\n" , mapNames[i].c_str(), fd); reuse = true ; } else { fd = bpf_create_map(md[i].type, mapNames[i].c_str(), md[i].key_size, md[i].value_size, md[i].max_entries, md[i].map_flags); ALOGD("bpf_create_map name %s, ret: %d\n" , mapNames[i].c_str(), fd); } ... if (!reuse) { ret = bpf_obj_pin(fd, mapPinLoc.c_str()); if (ret < 0 ) return ret; } mapFds[i] = fd; } return ret; }
为了避免map对象在bpfloader服务退出之后被销毁, 最后都会通过bpf_obj_pin把这些对象固定到/sys/fs/bpf文件节点.
加载代码到内核 要监听到内核事件, eBPF的ELF目标文件首先需要加载到内核, 然后在内核发生对应事件后触发对应的eBPF代码逻辑(内核的bpf虚拟机在执行代码之前会对目标文件代码进行校验, 以确保代码没有死循环等逻辑错误).
bpf_prog_load: 加载bpf程序到内核bpf_obj_pin: 将bpf程序固定到/sys/fs/bpf文件节点, 确保服务退出后, bpf程序依然可以正常执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 static int loadCodeSections (const char * elfPath, vector <codeSection>& cs, const string & license) { int ret, fd, kvers; if ((kvers = getMachineKvers()) < 0 ) return -1 ; string fname = pathToFilename(string (elfPath), true ); for (int i = 0 ; i < (int )cs.size(); i++) { string progPinLoc; bool reuse = false ; progPinLoc = string (BPF_FS_PATH) + "prog_" + fname + "_" + cs[i].name; if (access(progPinLoc.c_str(), F_OK) == 0 ) { fd = bpf_obj_get(progPinLoc.c_str()); ALOGD("New bpf prog load reusing prog %s, ret: %d\n" , cs[i].name.c_str(), fd); reuse = true ; } else { vector <char > log_buf(BPF_LOAD_LOG_SZ, 0 ); fd = bpf_prog_load(cs[i].type, cs[i].name.c_str(), (struct bpf_insn*)cs[i].data.data(), cs[i].data.size(), license.c_str(), kvers, 0 , log_buf.data(), log_buf.size()); ALOGD("New bpf core prog_load for %s (%s) returned: %d\n" , elfPath, cs[i].name.c_str(),fd); if (fd <= 0 ) ALOGE("bpf_prog_load: log_buf contents: %s\n" , (char *)log_buf.data()); } ... if (!reuse) { ret = bpf_obj_pin(fd, progPinLoc.c_str()); if (ret < 0 ) return ret; } cs[i].prog_fd = fd; } return 0 ; }
到这一步, eBPF完成了初始化, 目标文件也load到了内核, 此时只要内核有相应事件发生, 都会把结果保存到对应的map对象中. 用户进程只需要通过bpf的系统调用BPF_MAP_LOOKUP_ELEM等指令获取map对象中的数据.
Android如何使用eBPF统计流量 Android系统支持多种粒度的流量统计, 比如统计每个网卡的流量, 每个用户使用的流量, 有关Android流量统计的细节可以参考之前的博文Android是如何实现流量统计的 . 这里我们主要看下如何基于eBPF来实现对网卡以及每个用户的流量统计.
Android中有一个netd进程负责网络管理, 流量统计等功能, 在启动的时候会初始化一个TrafficController的类, 这个类就是负责流量统计功能的, 其在初始化的时候会创建几个BpfMap(实际是一个key-value的容器模板)对象, 用于保存不同流量统计的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Status TrafficController::initMaps () { std::lock_guard guard (mMutex) ; ... RETURN_IF_NOT_OK (mAppUidStatsMap.init (APP_UID_STATS_MAP_PATH)); RETURN_IF_NOT_OK (changeOwnerAndMode (APP_UID_STATS_MAP_PATH, AID_NET_BW_STATS, "AppUidStatsMap" , false )); RETURN_IF_NOT_OK (mStatsMapA.init (STATS_MAP_A_PATH)); RETURN_IF_NOT_OK (changeOwnerAndMode (STATS_MAP_A_PATH, AID_NET_BW_STATS, "StatsMapA" , false )); RETURN_IF_NOT_OK (mStatsMapB.init (STATS_MAP_B_PATH)); RETURN_IF_NOT_OK (changeOwnerAndMode (STATS_MAP_B_PATH, AID_NET_BW_STATS, "StatsMapB" , false )); RETURN_IF_NOT_OK (mIfaceIndexNameMap.init (IFACE_INDEX_NAME_MAP_PATH); RETURN_IF_NOT_OK (changeOwnerAndMode (IFACE_INDEX_NAME_MAP_PATH, AID_NET_BW_STATS,"IfaceIndexNameMap" , false )); RETURN_IF_NOT_OK (mIfaceStatsMap.init (IFACE_STATS_MAP_PATH)); RETURN_IF_NOT_OK (changeOwnerAndMode (IFACE_STATS_MAP_PATH, AID_NET_BW_STATS, "IfaceStatsMap" ,false )); ... return netdutils::status::ok; }
查看BpfMap模板(在BpfMap.h中定义)中的init函数可以知道, mAppUidStatsMap.init/mIfaceStatsMap.init实际是获取到固定在/sys/fs/bpf目录下的各个map对象节点文件描述符, 然后就可以通过该描述符来操作对应的map对象了.
1 2 3 4 5 6 7 8 9 10 11 12 netdutils::Status BpfMap<Key, Value>::init (const char * path) { mMapFd = base::unique_fd (mapRetrieve (path, 0 )); if (mMapFd == -1 ) { reset (); return netdutils::statusFromErrno ( errno, base::StringPrintf ("pinned map not accessible or does not exist: (%s)\n" , path)); } return netdutils::status::ok; }
对于cgroupskb类型的bpf程序, 还需要通过BPF_PROG_ATTACH命令把固定到/sys/fs/bpf的代码附着到对应的cgroup上(这样我们就可以监控特定cgroup上的进程的网络状态了):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 static Status initPrograms () std::string cg2_path; if (!CgroupGetControllerPath (CGROUPV2_CONTROLLER_NAME, &cg2_path)) { int ret = errno; ALOGE ("Failed to find cgroup v2 root" ); return statusFromErrno (ret, "Failed to find cgroup v2 root" ); } unique_fd cg_fd (open(cg2_path.c_str(), O_DIRECTORY | O_RDONLY | O_CLOEXEC)) ; if (cg_fd == -1 ) { int ret = errno; ALOGE ("Failed to open the cgroup directory: %s" , strerror (ret)); return statusFromErrno (ret, "Open the cgroup directory failed" ); } RETURN_IF_NOT_OK (attachProgramToCgroup (BPF_EGRESS_PROG_PATH, cg_fd, BPF_CGROUP_INET_EGRESS)); RETURN_IF_NOT_OK (attachProgramToCgroup (BPF_INGRESS_PROG_PATH, cg_fd, BPF_CGROUP_INET_INGRESS)); if (!access (CGROUP_SOCKET_PROG_PATH, F_OK)) { RETURN_IF_NOT_OK ( attachProgramToCgroup (CGROUP_SOCKET_PROG_PATH, cg_fd, BPF_CGROUP_INET_SOCK_CREATE)); } return netdutils::status::ok; }
cgroup是linux管理系统资源的资源分配与隔离方案, 在同一个cgroup的进程共享同样的CPU, 内存以及网络资源.
Android提供了一个libnetdbpf库封装了获取系统UID以及网卡的流量统计接口,提供给框架层使用, 比如想要获取某个UID的流量,可以使用bpfGetUidStats这个接口获取:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 int bpfGetUidStatsInternal (uid_t uid, Stats* stats, const BpfMap<uint32_t , StatsValue>& appUidStatsMap) auto statsEntry = appUidStatsMap.readValue (uid); if (isOk (statsEntry)) { stats->rxPackets = statsEntry.value ().rxPackets; stats->txPackets = statsEntry.value ().txPackets; stats->rxBytes = statsEntry.value ().rxBytes; stats->txBytes = statsEntry.value ().txBytes; } return statsEntry.status ().code () == ENOENT ? 0 : -statsEntry.status ().code (); } int bpfGetUidStats (uid_t uid, Stats* stats) BpfMap<uint32_t , StatsValue> appUidStatsMap ( mapRetrieve(APP_UID_STATS_MAP_PATH, BPF_OPEN_FLAGS)) if (!appUidStatsMap.isValid ()) { int ret = -errno; ALOGE ("Opening appUidStatsMap(%s) failed: %s" , APP_UID_STATS_MAP_PATH, strerror (errno)); return ret; } return bpfGetUidStatsInternal (uid, stats, appUidStatsMap); }
更多的实现细节可以参考BpfNetworkStats.cpp``, BpfMap.h以及TrafficController.cpp.
总结 这篇文章主要将了Android中eBPF程序的格式, 以及如何加载eBPF程序, 最后阐述了Android上如何利用eBPF来实现流量统计的功能. 对eBPF的逻辑与流程理清楚后, 在Android上开发自己的eBPF功能也就不是什么难事了.
参考文献