/* Wait for a connection to finish. One exception is TCP Fast Open * (passive side) where data is allowed to be sent before a connection * is fully established. */ if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) && !tcp_passive_fastopen(sk)) { err = sk_stream_wait_connect(sk, &timeo); if (err != 0) goto do_error; } ...
// 不断发送msg消息中的数据 while (msg_data_left(msg)) { int copy = 0; int max = size_goal;
skb = tcp_write_queue_tail(sk); if (tcp_send_head(sk)) { if (skb->ip_summed == CHECKSUM_NONE) max = mss_now; copy = max - skb->len; }
if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) { bool first_skb;
new_segment: /* Allocate new segment. If the interface is SG, * allocate skb fitting to single page. */ if (!sk_stream_memory_free(sk)) goto wait_for_sndbuf;
process_backlog = true; /* * Check whether we can use HW checksum. */ if (sk_check_csum_caps(sk)) skb->ip_summed = CHECKSUM_PARTIAL;
skb_entail(sk, skb); copy = size_goal; max = size_goal; ... /* Try to append data to the end of skb. */ if (copy > msg_data_left(msg)) copy = msg_data_left(msg);
/* Where to copy to? */ if (skb_availroom(skb) > 0) { /* We have some space in skb head. Superb! */ copy = min_t(int, copy, skb_availroom(skb)); err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy); if (err) goto do_fault; } elseif (!uarg || !uarg->zerocopy) { bool merge = true; int i = skb_shinfo(skb)->nr_frags; structpage_frag *pfrag = sk_page_frag(sk);
if (!sk_page_frag_refill(sk, pfrag)) goto wait_for_memory;
if (!skb_can_coalesce(skb, i, pfrag->page, pfrag->offset)) { if (i >= sysctl_max_skb_frags || !sg) { tcp_mark_push(tp, skb); goto new_segment; } merge = false; }
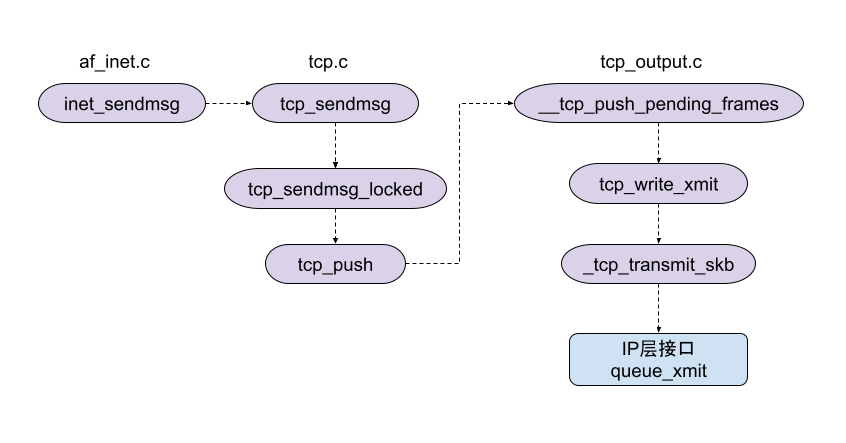
// tcp.c staticvoidtcp_push(struct sock *sk, int flags, int mss_now, int nonagle, int size_goal) { structtcp_sock *tp = tcp_sk(sk); structsk_buff *skb;
if (!tcp_send_head(sk)) return;
skb = tcp_write_queue_tail(sk); if (!(flags & MSG_MORE) || forced_push(tp)) tcp_mark_push(tp, skb); // 是否属于OOB(out of band)紧急数据 tcp_mark_urg(tp, flags);
if (tcp_should_autocork(sk, skb, size_goal)) {
/* avoid atomic op if TSQ_THROTTLED bit is already set */ if (!test_bit(TSQ_THROTTLED, &sk->sk_tsq_flags)) { NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPAUTOCORKING); set_bit(TSQ_THROTTLED, &sk->sk_tsq_flags); } /* It is possible TX completion already happened * before we set TSQ_THROTTLED. */ if (refcount_read(&sk->sk_wmem_alloc) > skb->truesize) return; }
// tcp_output.c void __tcp_push_pending_frames(struct sock *sk, unsignedint cur_mss, int nonagle) { /* If we are closed, the bytes will have to remain here. * In time closedown will finish, we empty the write queue and * all will be happy. */ if (unlikely(sk->sk_state == TCP_CLOSE)) return;
if (tcp_write_xmit(sk, cur_mss, nonagle, 0, sk_gfp_mask(sk, GFP_ATOMIC))) tcp_check_probe_timer(sk); }
if (unlikely(tp->repair) && tp->repair_queue == TCP_SEND_QUEUE) { /* "skb_mstamp" is used as a start point for the retransmit timer */ skb->skb_mstamp = tp->tcp_mstamp; goto repair; /* Skip network transmission */ }
cwnd_quota = tcp_cwnd_test(tp, skb); if (!cwnd_quota) { if (push_one == 2) /* Force out a loss probe pkt. */ cwnd_quota = 1; else break; }
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) { is_rwnd_limited = true; break; }
if (tso_segs == 1) { if (unlikely(!tcp_nagle_test(tp, skb, mss_now, (tcp_skb_is_last(sk, skb) ? nonagle : TCP_NAGLE_PUSH)))) break; } else { if (!push_one && tcp_tso_should_defer(sk, skb, &is_cwnd_limited, &is_rwnd_limited, max_segs)) break; }
if (test_bit(TCP_TSQ_DEFERRED, &sk->sk_tsq_flags)) clear_bit(TCP_TSQ_DEFERRED, &sk->sk_tsq_flags); if (tcp_small_queue_check(sk, skb, 0)) break;
/* Argh, we hit an empty skb(), presumably a thread * is sleeping in sendmsg()/sk_stream_wait_memory(). * We do not want to send a pure-ack packet and have * a strange looking rtx queue with empty packet(s). */ if (TCP_SKB_CB(skb)->end_seq == TCP_SKB_CB(skb)->seq) break;
// 发送数据 if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp))) break;
repair: /* Advance the send_head. This one is sent out. * This call will increment packets_out. */ tcp_event_new_data_sent(sk, skb);
/* if no packet is in qdisc/device queue, then allow XPS to select * another queue. We can be called from tcp_tsq_handler() * which holds one reference to sk_wmem_alloc. * * TODO: Ideally, in-flight pure ACK packets should not matter here. * One way to get this would be to set skb->truesize = 2 on them. */ skb->ooo_okay = sk_wmem_alloc_get(sk) < SKB_TRUESIZE(1);
/* If we had to use memory reserve to allocate this skb, * this might cause drops if packet is looped back : * Other socket might not have SOCK_MEMALLOC. * Packets not looped back do not care about pfmemalloc. */ skb->pfmemalloc = 0;
if (after(tcb->end_seq, tp->snd_nxt) || tcb->seq == tcb->end_seq) TCP_ADD_STATS(sock_net(sk), TCP_MIB_OUTSEGS, tcp_skb_pcount(skb));
tp->segs_out += tcp_skb_pcount(skb); /* OK, its time to fill skb_shinfo(skb)->gso_{segs|size} */ skb_shinfo(skb)->gso_segs = tcp_skb_pcount(skb); skb_shinfo(skb)->gso_size = tcp_skb_mss(skb);
/* Our usage of tstamp should remain private */ skb->tstamp = 0;
/* Cleanup our debris for IP stacks */ memset(skb->cb, 0, max(sizeof(struct inet_skb_parm), sizeof(struct inet6_skb_parm)));
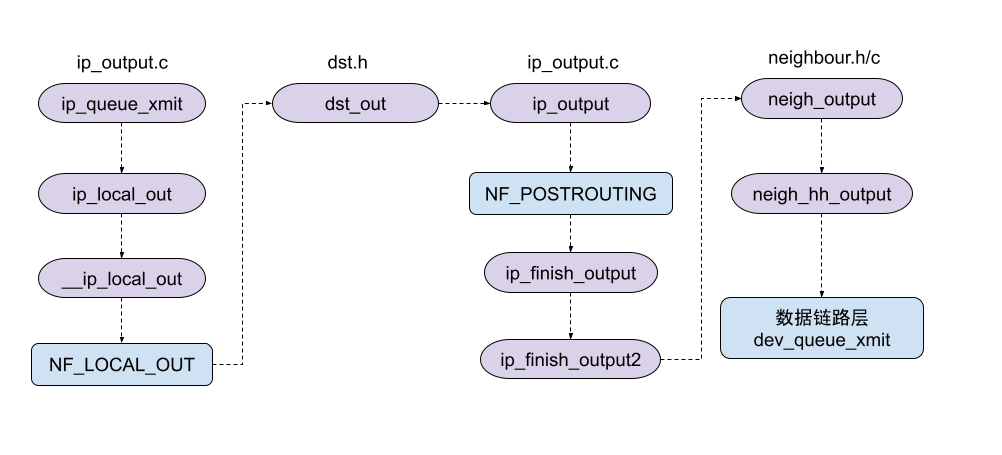
/* Skip all of this if the packet is already routed, * f.e. by something like SCTP. */ rcu_read_lock(); inet_opt = rcu_dereference(inet->inet_opt); fl4 = &fl->u.ip4; rt = skb_rtable(skb); if (rt) goto packet_routed;
/* Make sure we can route this packet. */ rt = (struct rtable *)__sk_dst_check(sk, 0); if (!rt) { __be32 daddr;
/* Use correct destination address if we have options. */ daddr = inet->inet_daddr; if (inet_opt && inet_opt->opt.srr) daddr = inet_opt->opt.faddr;
/* If this fails, retransmit mechanism of transport layer will * keep trying until route appears or the connection times * itself out. */ rt = ip_route_output_ports(net, fl4, sk, daddr, inet->inet_saddr, inet->inet_dport, inet->inet_sport, sk->sk_protocol, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if); if (IS_ERR(rt)) goto no_route; sk_setup_caps(sk, &rt->dst); } skb_dst_set_noref(skb, &rt->dst);
packet_routed: if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway) goto no_route;
/* if egress device is enslaved to an L3 master device pass the * skb to its handler for processing */ skb = l3mdev_ip_out(sk, skb); if (unlikely(!skb)) return0;
do { seq = read_seqbegin(&hh->hh_lock); hh_len = READ_ONCE(hh->hh_len); if (likely(hh_len <= HH_DATA_MOD)) { hh_alen = HH_DATA_MOD;
/* skb_push() would proceed silently if we have room for * the unaligned size but not for the aligned size: * check headroom explicitly. */ if (likely(skb_headroom(skb) >= HH_DATA_MOD)) { /* this is inlined by gcc */ memcpy(skb->data - HH_DATA_MOD, hh->hh_data, HH_DATA_MOD); } } else { hh_alen = HH_DATA_ALIGN(hh_len);
if (likely(skb_headroom(skb) >= hh_alen)) { memcpy(skb->data - hh_alen, hh->hh_data, hh_alen); } } } while (read_seqretry(&hh->hh_lock, seq));
if (WARN_ON_ONCE(skb_headroom(skb) < hh_alen)) { kfree_skb(skb); return NET_XMIT_DROP; }
if (unlikely(skb_shinfo(skb)->tx_flags & SKBTX_SCHED_TSTAMP)) __skb_tstamp_tx(skb, NULL, skb->sk, SCM_TSTAMP_SCHED);
/* Disable soft irqs for various locks below. Also * stops preemption for RCU. */ rcu_read_lock_bh(); // 更新skbuff的优先级(根据cgroup定义的优先级) skb_update_prio(skb);
qdisc_pkt_len_init(skb);
/* If device/qdisc don't need skb->dst, release it right now while * its hot in this cpu cache. */ if (dev->priv_flags & IFF_XMIT_DST_RELEASE) skb_dst_drop(skb); else skb_dst_force(skb);
trace_net_dev_queue(skb); if (q->enqueue) { rc = __dev_xmit_skb(skb, q, dev, txq); goto out; }
/* The device has no queue. Common case for software devices: * loopback, all the sorts of tunnels... * Really, it is unlikely that netif_tx_lock protection is necessary * here. (f.e. loopback and IP tunnels are clean ignoring statistics * counters.) * However, it is possible, that they rely on protection * made by us here. * Check this and shot the lock. It is not prone from deadlocks. *Either shot noqueue qdisc, it is even simpler 8) */ if (dev->flags & IFF_UP) { int cpu = smp_processor_id(); /* ok because BHs are off */
if (txq->xmit_lock_owner != cpu) { if (unlikely(__this_cpu_read(xmit_recursion) > XMIT_RECURSION_LIMIT)) goto recursion_alert;
skb = validate_xmit_skb(skb, dev); if (!skb) goto out;
HARD_TX_LOCK(dev, txq, cpu);
if (!netif_xmit_stopped(txq)) { __this_cpu_inc(xmit_recursion); skb = dev_hard_start_xmit(skb, dev, txq, &rc); __this_cpu_dec(xmit_recursion); if (dev_xmit_complete(rc)) { HARD_TX_UNLOCK(dev, txq); goto out; } } HARD_TX_UNLOCK(dev, txq); net_crit_ratelimited("Virtual device %s asks to queue packet!\n", dev->name); } else { /* Recursion is detected! It is possible, * unfortunately */ recursion_alert: net_crit_ratelimited("Dead loop on virtual device %s, fix it urgently!\n", dev->name); } }
qdisc_calculate_pkt_len(skb, q); /* * Heuristic to force contended enqueues to serialize on a * separate lock before trying to get qdisc main lock. * This permits qdisc->running owner to get the lock more * often and dequeue packets faster. */ contended = qdisc_is_running(q); if (unlikely(contended)) spin_lock(&q->busylock);
spin_lock(root_lock); if (unlikely(test_bit(__QDISC_STATE_DEACTIVATED, &q->state))) { __qdisc_drop(skb, &to_free); rc = NET_XMIT_DROP; } elseif ((q->flags & TCQ_F_CAN_BYPASS) && !qdisc_qlen(q) && qdisc_run_begin(q)) { /* * This is a work-conserving queue; there are no old skbs * waiting to be sent out; and the qdisc is not running - * xmit the skb directly. */
qdisc_bstats_update(q, skb);
if (sch_direct_xmit(skb, q, dev, txq, root_lock, true)) { if (unlikely(contended)) { spin_unlock(&q->busylock); contended = false; } __qdisc_run(q); } else qdisc_run_end(q);
rc = NET_XMIT_SUCCESS; } else { rc = q->enqueue(skb, q, &to_free) & NET_XMIT_MASK; if (qdisc_run_begin(q)) { if (unlikely(contended)) { spin_unlock(&q->busylock); contended = false; } __qdisc_run(q); } } spin_unlock(root_lock); if (unlikely(to_free)) kfree_skb_list(to_free); if (unlikely(contended)) spin_unlock(&q->busylock); return rc; }
while (head) { structQdisc *q = head; spinlock_t *root_lock;
head = head->next_sched;
root_lock = qdisc_lock(q); spin_lock(root_lock); /* We need to make sure head->next_sched is read * before clearing __QDISC_STATE_SCHED */ smp_mb__before_atomic(); clear_bit(__QDISC_STATE_SCHED, &q->state); qdisc_run(q); spin_unlock(root_lock); } } }