
Java诞生于互联网兴盛的上世纪90年代,为了在不同终端设备上运行Java程序,其在设计之初,就考虑到了语言的可移植性,确保编写完后,可以在任何平台上运行。随着互联网时代的来临,Java因其平台无关性(platform independence), 安全性(security)、网络可移动性(network mobility)以及内存自动管理(Garbage Collection)等特征而得到了广泛的应用。那么, Java的这些特性究竟是如何实现的?相比早前的C/C++等编译型语言,Java程序首先被编译成一个个包含了字节码(bytecode)的.class文件,运行时,.class文件被加载Java虚拟机(Java Virtual Machine)上执行。实际上,任何其他语言只要能够编译成JVM能够识别的bytecode, JVM都可以执行。从这个角度来看,JVM封装了平台的硬件细节,使得Java程序在编译完后可以在任何有Java运行环境的(Java Runtime Enviroment, JRE)平台上运行,无需再关心不同平台的差异。接下来,就来看下,JVM的具体结构以及各个组成部分的功能。
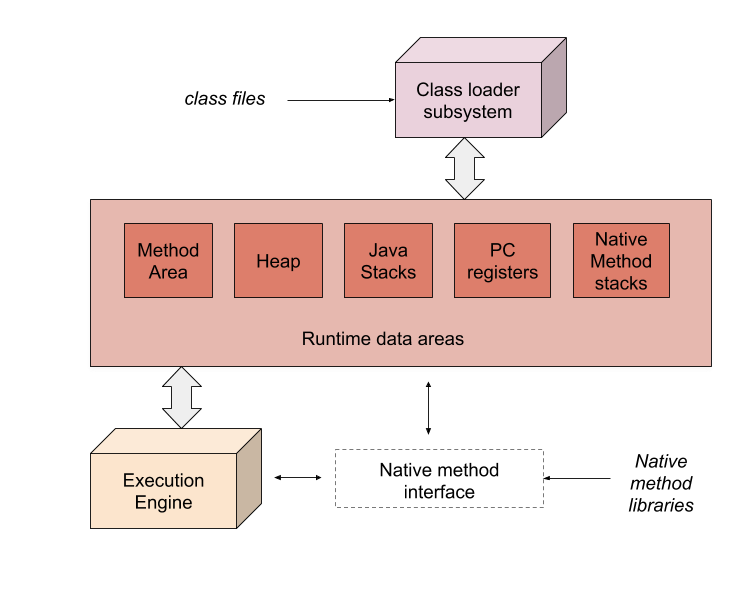
下图是JVM的结构图, 其主要由如下三个部分组成:
- 类加载系统(class loader subsystem):负责加载class文件;
- 运行时数据区: (Runtime data areas): 运行程序运行时的内存区域,保存如类实例、类名、方法参数、方法代码以及局部变量等,主要分为方法区(
method area)、堆(heap)、栈(Java Stacks)等几个区域,对于不同的虚拟机实现运行时数据区可能并不一样。 - 执行系统(Execution Engine):负责执行JVM指令
类文件
Java类文件.class是由.java文件编译过来的二进制文件,其中每个字符都只有8-bit,因此类文件字节流也叫做bytecode,每个数据项都是依次相邻存储,不会有任何填充位,如果一个数据项有多个字节,则将其分成多个连续的字节存放(采用高位在前的bit-endian编码)。这中连续存放的格式使得类文件更加紧凑,方便在网络中传输。
类文件的定义确保了不管在何种系统下编译产生,JVM都能够正确的加载、解析执行;因此,其他语言通过编译产生同样的.class文件,JVM同样能够解析执行。
那么,类文件具体包含哪些信息了?Java文件中的变量、方法名以及方法中的代码又是如何存储的?JVM虚拟机规范给出了类文件的结构:
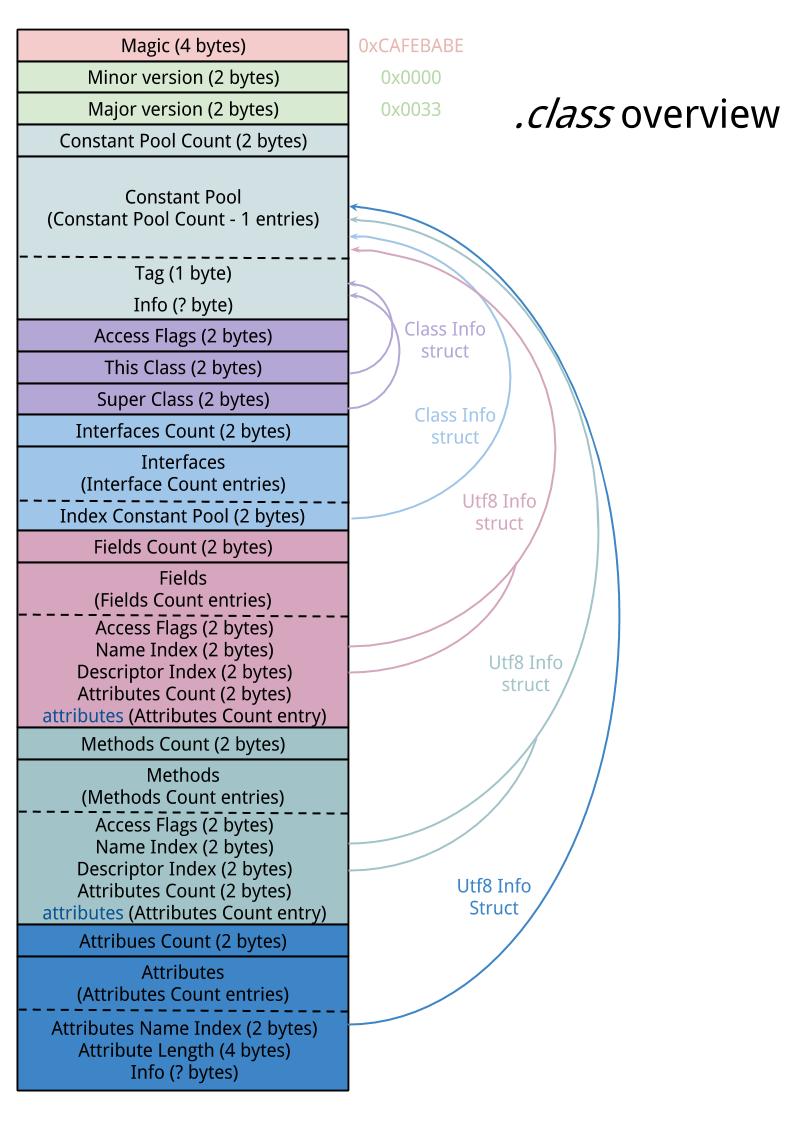
这其中,u1,u2,u4分别表示一个字节、两个字节以及四个字节长的无符号整数,可以看出,类文件实际上是一个由不同长度的数据项组成,每个数据项都有一个类型(type),名称(name)以及数量(count),比如类文件魔数magic是一个类型为u2、数量为1的数据项。类文件就是按照上述顺序存储的,我们来看看各个数据项的具体信息:
魔数(magic)
类文件的开头四个字节总是它的魔数(magic number)0xCAFEBABE,魔数用于识别某个文件是否是类文件;如果一个文件的魔术不是0xCAFEBABE,则肯定不是类文件。
minor_version/major_version
第二个四个字节分别是次版本号与主版本号,用于表示Java对应的版本,如果版本号不再有效的范围内,JVM会直接拒绝加载该类文件。
常量池(constant pool)
顾名思义,常量池包含了类或者接口中的常量,如字符串、final变量、类名以及方法名等。常量池是由一个个常量项组成的表,该表大小为constant_pool_count,表索引的位置是从1到constant_pool_count-1,索引位置0是预留位置,一般不使用。 每个常量项都是由一个字节的tag与一个字节数组构成:
1 |
|
info数组的大小是根据不同tag对应的数据项所占空间大小决定的,常量池有如下几种tag类型:
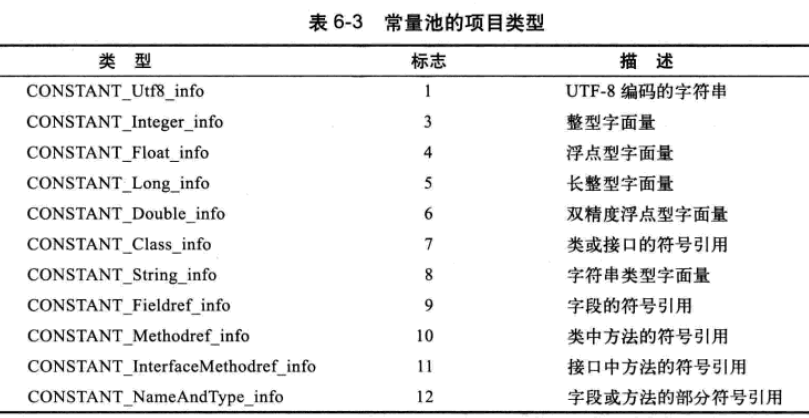
例如,标签CONSTANT_Class,用于表示一个类或者接口名称,其主要有两部分组成:
- 长度为
u1的标签值; - 长度为
u2的名称索引(指向常量表中的某个位置)
1 |
|
从这里也可以看到, 对于Java语言来说,类名或者接口名的最大长度为255个字符。
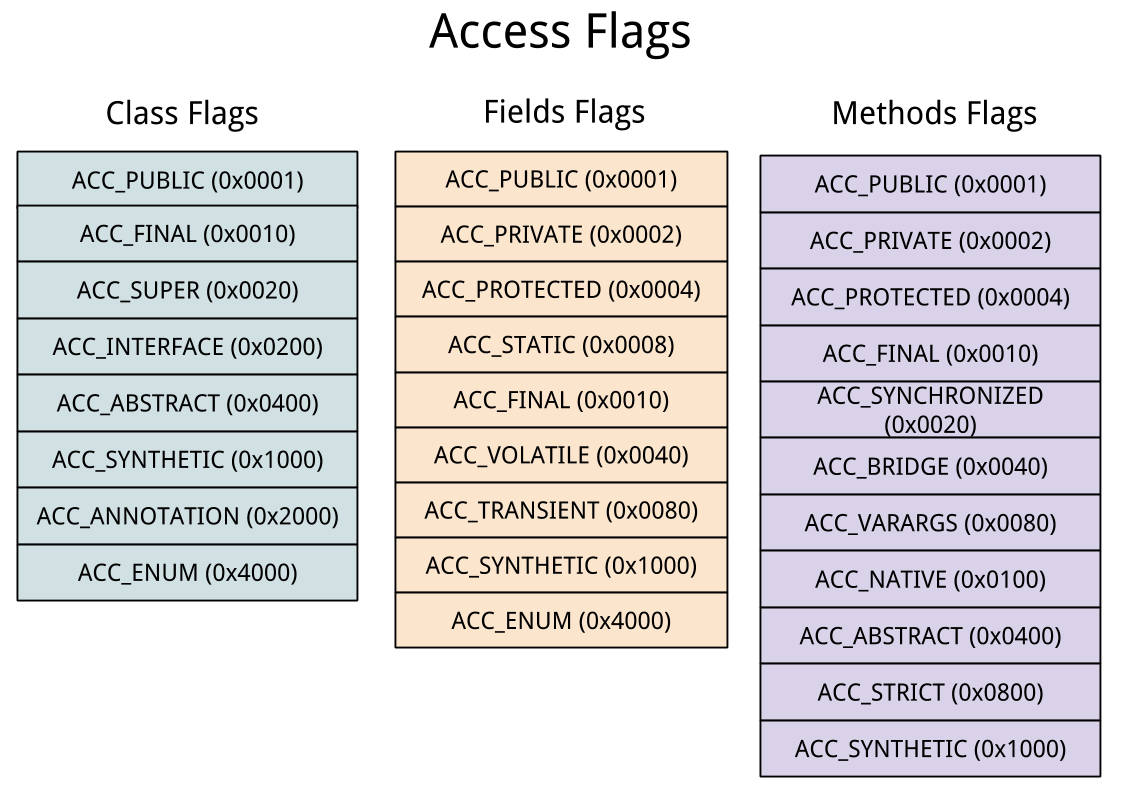
access_flags
类型标志,占有2个字节,用于表示这个类或者接口的类型:
this_class
在类型标志之后的两个字节,是this_class数据项,用于表示类名,该数据项实际是一个constant pool的索引,其指向一个CONSTANT_Class类。
super_class
super_class占两个字节,跟this_class一样,也是一个常量池的索引,用于表示一个类的父类的全限定名(例如java.lang.object对应的全限定名为java/lang/object)。在Java中,所有类的基类都是java.lang.object,因此对于所有类,该索引都指向一个java.lang.object的CONSTANT_Class_info常量项,但是对于Object类本身来说,该值为0。
interfaces_count and interfaces
super_class之后是interfaces_count,表示类所实现的接口或者在类中定义的接口数。接着interfaces_count是接口数据索引数组interfaces,该数组包含了所有指向常量池中接口描述信息CONTANT_Class_info的索引。
在接口信息之后还包含了类似的数据项fields_count/fields、methods_count/methods、attributes_count/attributes。
运行时数据区
类文件加载完成后, JVM需要为程序新建内存区域,保存诸如方法名、类名、类实例、方法参数、返回值以及局部变量等。JVM将这些运行时的内存主要分为几个区域(需要注意的是,不同的虚拟机实现运行时数据区可能并不相同):

- 方法区(method area):方法区在JVM启动时候创建,用于存储每个类的运行时常量池(constant pool),变量以及方法信息以及相应的代码。方法区为所有线程共享。如果方法区内存不足,不能满足分配请求时,JVM会抛出一个
OutOfMemoryError异常; - 堆区(Heap):JVM启动时创建,所有引用类对象的创建都是在堆区进行的,该区的内存分配与释放都是由GC(Gabage Collector)来负责管理的。与方法区一样,堆区也是为所有线程共享的。当JVM的内存管理系统无法分配所需内存时,则抛出
OutOfMemoryError异常; - 栈(Java Stacks):新的进程创建时,JVM为其创建一个栈区,用于保存线程的本地变量以及运行结果,返回值等。Java栈是由栈帧(Stack frames)组成的,一个栈帧包含了Java方法调用的状态,当一个线程调用某个方法时,JVM将一个新的栈帧压入栈区;当调用方法完成后,则将该栈帧从栈中弹出。如果一个线程所需的栈内存超过了JVM栈最大能够提供的大小,则会抛出
StackOverflowError; - 程序计数器寄存器(PC registers):每个线程都有自己的程序计数器,用于保存当前线程所运行方法的地址,如果该方法不是native的,程序计数器保存的是线程当前正在执行的方法地址;而对于native方法,程序计数器的值是不定的;
- 本地方法栈(Native Method Stacks):一个线程调用其他语言如C/C++的方法时, JVM会为其创建一个本地方法栈,用于保存临时变量以及返回值等;
- 运行时常量池(run-time constant pool): 每个类与接口在类文件中都有一个
constant_pool的表,用于存放数值或者方法的引用。每个常量池所需内存都是从JVM的方法区中分配的,JVM会在类或者接口创建的时候为其构造一个运行时常量池。当常量池内存分配不足时,JVM会抛出一个OutOfMemoryError的异常。
执行系统
执行系统(Execution Engine)是JVM的核心部分,主要负责执行虚拟机指令。对于每个线程,都有自己的执行系统实例。执行系统可能直接执行字节码指令,或者执行本地代码,也可以通过JIT执行编译后的本地代码。JVM规范对具体如何执行指令并没有做明确的规定,只是提供了指令的定义。
JVM中的指令都有一个助记符,一般都是由一个单字节操作码(opcode),跟着零个或者多个操作数(operands),多数的指令都有操作码,没有操作数。大部分指令的操作码都在首个字母标识了该指令对应的动作,例如,iload指令加载局部变量值的操作栈上,这个局部变量的值必须是int,与此类似的指令还有fload, dload等:
- int型指令对应开头为
*i*; - float型指令对应为
*f*; - double型指令对应为
**d**; - long型指令对应为
l; - short型指令对应
s; - byte型指令对应
b; - char型指令对应
c; - 引用类型指令对应
a;
来看一个JVM指令的具体实例,有如下一个类SayHello.java:
1 |
|
在对应文件目录输入指令javac SayHello.java,得到一个SayHello.class的文件,接着利用反编译工具javap,输入指令javap -c SayHello.class,得到反汇编后的字节码:
1 |
|