/* * It's bad if compaction run occurs and fails. The most likely reason * is that pages exist, but not enough to satisfy watermarks. */ count_vm_event(COMPACTFAIL);
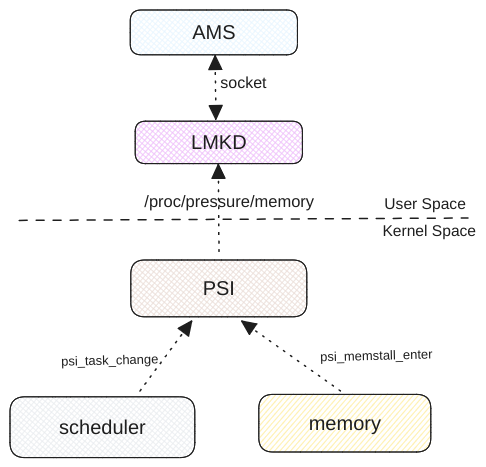
staticboolinit_monitors(){ /* Try to use psi monitor first if kernel has it */ use_psi_monitors = GET_LMK_PROPERTY(bool, "use_psi", true) && init_psi_monitors(); /* Fall back to vmpressure */ if (!use_psi_monitors && (!init_mp_common(VMPRESS_LEVEL_LOW) || !init_mp_common(VMPRESS_LEVEL_MEDIUM) || !init_mp_common(VMPRESS_LEVEL_CRITICAL))) { ALOGE("Kernel does not support memory pressure events or in-kernel low memory killer"); returnfalse; } if (use_psi_monitors) { ALOGI("Using psi monitors for memory pressure detection"); } else { ALOGI("Using vmpressure for memory pressure detection"); } returntrue; }
staticboolinit_psi_monitors(){ /* * When PSI is used on low-ram devices or on high-end devices without memfree levels * use new kill strategy based on zone watermarks, free swap and thrashing stats */ bool use_new_strategy = GET_LMK_PROPERTY(bool, "use_new_strategy", low_ram_device || !use_minfree_levels);
/* In default PSI mode override stall amounts using system properties */ if (use_new_strategy) { /* Do not use low pressure level */ psi_thresholds[VMPRESS_LEVEL_LOW].threshold_ms = 0; psi_thresholds[VMPRESS_LEVEL_MEDIUM].threshold_ms = psi_partial_stall_ms; psi_thresholds[VMPRESS_LEVEL_CRITICAL].threshold_ms = psi_complete_stall_ms; }
if (!init_mp_psi(VMPRESS_LEVEL_LOW, use_new_strategy)) { returnfalse; } if (!init_mp_psi(VMPRESS_LEVEL_MEDIUM, use_new_strategy)) { destroy_mp_psi(VMPRESS_LEVEL_LOW); returnfalse; } if (!init_mp_psi(VMPRESS_LEVEL_CRITICAL, use_new_strategy)) { destroy_mp_psi(VMPRESS_LEVEL_MEDIUM); destroy_mp_psi(VMPRESS_LEVEL_LOW); returnfalse; } returntrue; }
bool kill_pending = is_kill_pending(); if (kill_pending && (kill_timeout_ms == 0 || get_time_diff_ms(&last_kill_tm, &curr_tm) < static_cast<long>(kill_timeout_ms))) { /* Skip while still killing a process */ wi.skipped_wakeups++; goto no_kill; } /* * Process is dead or kill timeout is over, stop waiting. This has no effect if pidfds are * supported and death notification already caused waiting to stop. */ stop_wait_for_proc_kill(!kill_pending);
if (vmstat_parse(&vs) < 0) { ALOGE("Failed to parse vmstat!"); return; } /* Starting 5.9 kernel workingset_refault vmstat field was renamed workingset_refault_file */ workingset_refault_file = vs.field.workingset_refault ? : vs.field.workingset_refault_file;
if (meminfo_parse(&mi) < 0) { ALOGE("Failed to parse meminfo!"); return; }
/* Reset states after process got killed */ if (killing) { killing = false; cycle_after_kill = true; /* Reset file-backed pagecache size and refault amounts after a kill */ base_file_lru = vs.field.nr_inactive_file + vs.field.nr_active_file; init_ws_refault = workingset_refault_file; thrashing_reset_tm = curr_tm; prev_thrash_growth = 0; }
/* Identify reclaim state */ if (vs.field.pgscan_direct > init_pgscan_direct) { init_pgscan_direct = vs.field.pgscan_direct; init_pgscan_kswapd = vs.field.pgscan_kswapd; reclaim = DIRECT_RECLAIM; } elseif (vs.field.pgscan_kswapd > init_pgscan_kswapd) { init_pgscan_kswapd = vs.field.pgscan_kswapd; reclaim = KSWAPD_RECLAIM; } elseif (workingset_refault_file == prev_workingset_refault) { /* * Device is not thrashing and not reclaiming, bail out early until we see these stats * changing */ goto no_kill; }
/* * It's possible we fail to find an eligible process to kill (ex. no process is * above oom_adj_min). When this happens, we should retry to find a new process * for a kill whenever a new eligible process is available. This is especially * important for a slow growing refault case. While retrying, we should keep * monitoring new thrashing counter as someone could release the memory to mitigate * the thrashing. Thus, when thrashing reset window comes, we decay the prev thrashing * counter by window counts. If the counter is still greater than thrashing limit, * we preserve the current prev_thrash counter so we will retry kill again. Otherwise, * we reset the prev_thrash counter so we will stop retrying. */ since_thrashing_reset_ms = get_time_diff_ms(&thrashing_reset_tm, &curr_tm); if (since_thrashing_reset_ms > THRASHING_RESET_INTERVAL_MS) { long windows_passed; /* Calculate prev_thrash_growth if we crossed THRASHING_RESET_INTERVAL_MS */ prev_thrash_growth = (workingset_refault_file - init_ws_refault) * 100 / (base_file_lru + 1); windows_passed = (since_thrashing_reset_ms / THRASHING_RESET_INTERVAL_MS); /* * Decay prev_thrashing unless over-the-limit thrashing was registered in the window we * just crossed, which means there were no eligible processes to kill. We preserve the * counter in that case to ensure a kill if a new eligible process appears. */ if (windows_passed > 1 || prev_thrash_growth < thrashing_limit) { prev_thrash_growth >>= windows_passed; }
/* Record file-backed pagecache size when crossing THRASHING_RESET_INTERVAL_MS */ base_file_lru = vs.field.nr_inactive_file + vs.field.nr_active_file; init_ws_refault = workingset_refault_file; thrashing_reset_tm = curr_tm; thrashing_limit = thrashing_limit_pct; } else { /* Calculate what % of the file-backed pagecache refaulted so far */ thrashing = (workingset_refault_file - init_ws_refault) * 100 / (base_file_lru + 1); } /* Add previous cycle's decayed thrashing amount */ thrashing += prev_thrash_growth; if (max_thrashing < thrashing) { max_thrashing = thrashing; }
/* * Refresh watermarks once per min in case user updated one of the margins. * TODO: b/140521024 replace this periodic update with an API for AMS to notify LMKD * that zone watermarks were changed by the system software. */ if (watermarks.high_wmark == 0 || get_time_diff_ms(&wmark_update_tm, &curr_tm) > 60000) { structzoneinfo zi;
if (zoneinfo_parse(&zi) < 0) { ALOGE("Failed to parse zoneinfo!"); return; }