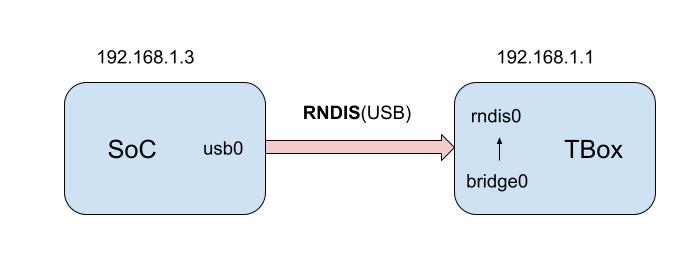
// ping.c intping_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int noblock, int flags, int *addr_len) { structinet_sock *isk = inet_sk(sk); int family = sk->sk_family; structsk_buff *skb; int copied, err;
// core/datagram.c structsk_buff *__skb_try_recv_datagram(structsock *sk, unsignedintflags, void (*destructor)(structsock *sk, structsk_buff *skb), int *peeked, int *off, int *err, structsk_buff **last) { structsk_buff_head *queue = &sk->sk_receive_queue; structsk_buff *skb; unsignedlong cpu_flags; /* * Caller is allowed not to check sk->sk_err before skb_recv_datagram() */ int error = sock_error(sk);
if (error) goto no_packet;
*peeked = 0; do { /* Again only user level code calls this function, so nothing * interrupt level will suddenly eat the receive_queue. * * Look at current nfs client by the way... * However, this function was correct in any case. 8) */ spin_lock_irqsave(&queue->lock, cpu_flags); skb = __skb_try_recv_from_queue(sk, queue, flags, destructor, peeked, off, &error, last); spin_unlock_irqrestore(&queue->lock, cpu_flags); if (error) goto no_packet; if (skb) return skb;
if (!sk_can_busy_loop(sk)) break;
sk_busy_loop(sk, flags & MSG_DONTWAIT); } while (READ_ONCE(sk->sk_receive_queue.prev) != *last);
/* When the interface is in promisc. mode, drop all the crap * that it receives, do not try to analyse it. */ if (skb->pkt_type == PACKET_OTHERHOST) goto drop;
net = dev_net(dev); __IP_UPD_PO_STATS(net, IPSTATS_MIB_IN, skb->len);
if (!pskb_may_pull(skb, sizeof(struct iphdr))) goto inhdr_error;
iph = ip_hdr(skb);
/* * RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum. * * Is the datagram acceptable? * * 1. Length at least the size of an ip header * 2. Version of 4 * 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums] * 4. Doesn't have a bogus length */
if (iph->ihl < 5 || iph->version != 4) goto inhdr_error;
if (!pskb_may_pull(skb, iph->ihl*4)) goto inhdr_error;
iph = ip_hdr(skb);
if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl))) goto csum_error;
len = ntohs(iph->tot_len); if (skb->len < len) { __IP_INC_STATS(net, IPSTATS_MIB_INTRUNCATEDPKTS); goto drop; } elseif (len < (iph->ihl*4)) goto inhdr_error;
/* Our transport medium may have padded the buffer out. Now we know it * is IP we can trim to the true length of the frame. * Note this now means skb->len holds ntohs(iph->tot_len). */ if (pskb_trim_rcsum(skb, len)) { __IP_INC_STATS(net, IPSTATS_MIB_INDISCARDS); goto drop; }
/* * Some variants of DSA tagging don't have an ethertype field * at all, so we check here whether one of those tagging * variants has been configured on the receiving interface, * and if so, set skb->protocol without looking at the packet. */ if (unlikely(netdev_uses_dsa(dev))) return htons(ETH_P_XDSA);
if (likely(eth_proto_is_802_3(eth->h_proto))) return eth->h_proto;
/* * This is a magic hack to spot IPX packets. Older Novell breaks * the protocol design and runs IPX over 802.3 without an 802.2 LLC * layer. We look for FFFF which isn't a used 802.2 SSAP/DSAP. This * won't work for fault tolerant netware but does for the rest. */ sap = skb_header_pointer(skb, 0, sizeof(*sap), &_service_access_point); if (sap && *sap == 0xFFFF) return htons(ETH_P_802_3);
/* * Real 802.2 LLC */ return htons(ETH_P_802_2); } EXPORT_SYMBOL(eth_type_trans);
/* Passes this packet up the stack, updating its accounting. * Some link protocols batch packets, so their rx_fixup paths * can return clones as well as just modify the original skb. */ voidusbnet_skb_return(struct usbnet *dev, struct sk_buff *skb) { structpcpu_sw_netstats *stats64 = this_cpu_ptr(dev->stats64); unsignedlong flags; int status; structtimespec64now;
if (test_bit(EVENT_RX_PAUSED, &dev->flags)) { dbg_log_string("skb %pK added to pause list", skb); skb_queue_tail(&dev->rxq_pause, skb); return; }
/* only update if unset to allow minidriver rx_fixup override */ if (skb->protocol == 0) skb->protocol = eth_type_trans (skb, dev->net);