
缓存(Memory Cache)在一般意义上是指一种用于存储当前或者历史数据的硬件或者软件结构,其目的是加速数据的存取,提升系统效率。目前大多数的计算机系统都会在软件或者硬件层面集成有各种cache, 比如:
- L2(Level 2 cache,3-10个CPU周期)作为L1(Level 1 cache, 1-3个CPU周期)的缓存, 同样L3又作为L2的缓存, 从而形成一个多级缓存的结构
- TLB(Translation Lookaside Buffer)用于系统页表查找的缓存, 可以加速虚拟内存与物理内存的地址转换
- Main Memory(主存)是磁盘数据的缓存, 保存了部分使用的磁盘数据, 改善系统运行的性能
一般来说, 现代的多核CPU系统都有多级的缓存结构, 简图如下:
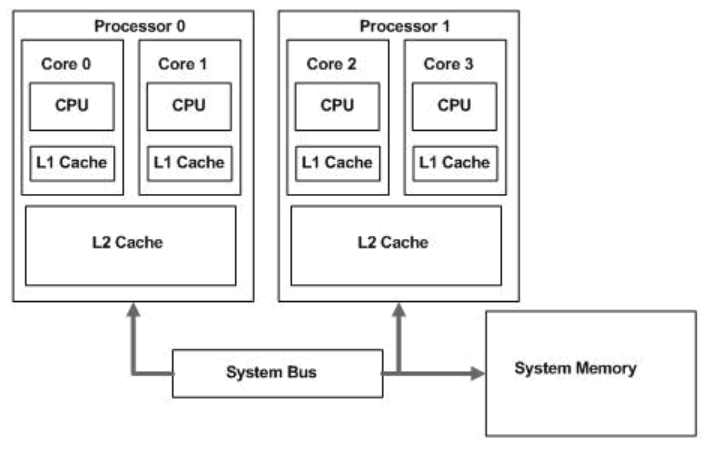
这篇文章将要讨论的cache是指CPU与主内存之间的一种基于SRAM(Static Random Access Memory)存储结构。
自计算机诞生以来,CPU的性能大致都按照摩尔定律以每年50%的速度递增,而主内存RAM(Random Access Memory)的性能增速却只有7%,因此在CPU性能与主内存性能之间渐渐形成了一个鸿沟:
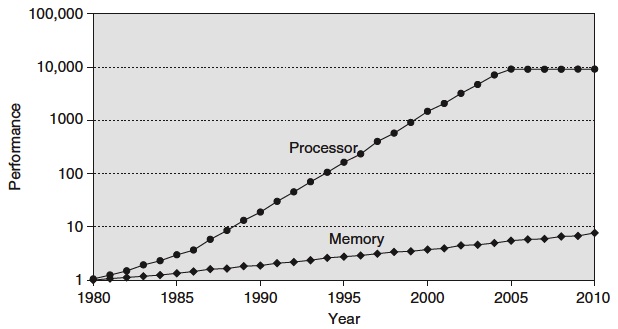
1980年CPU中尚无cache; 到1995年CPU开始有两级cache
从主内存中读取数据通常需要花费50~200个CPU周期,利用cache来保存CPU最近使用的数据或者指令,如果cache中存在所需数据(指令),则直接返回给CPU;如果不存在相应的数据,则从主内存中获取,从而提升CPU效率。这样Cache, Main Memory以及Disk(磁盘)之间就形成了通常被称为”Memory Hierarchy“的存储层次化的结构:
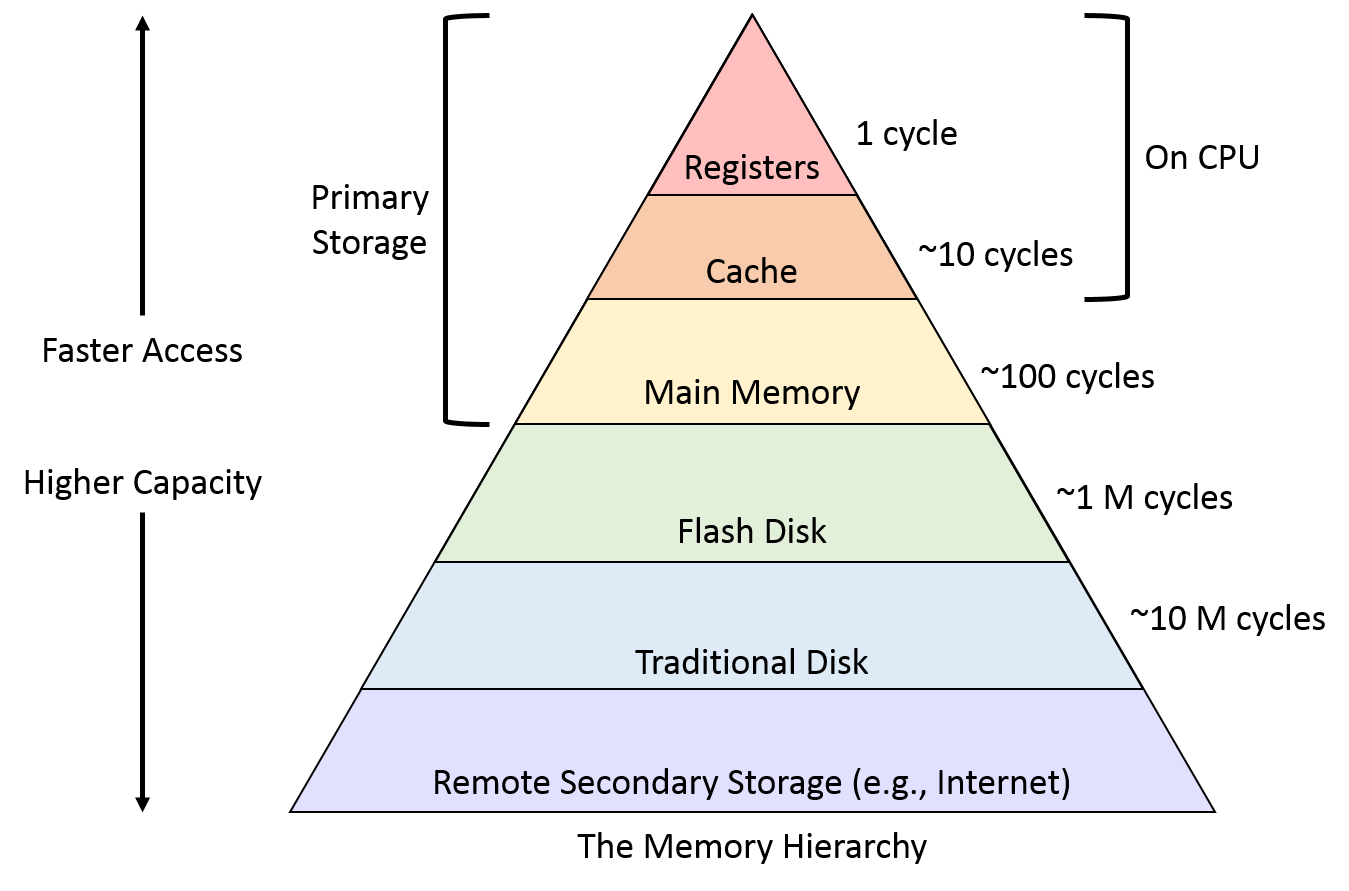
那么,为什么cache能够提升CPU的运行效率?这里边依靠的是程序运行时的一个基本原理:引用的局部性(
Locality of reference):相近的或者最近被访问的内存区域通常就是下一次需要访问的内存区域。最常见的是两种局部性:
- 时间局部性(Temporal locality) : 最近被访问的内存区域,很可能在稍后的时间里被引用;
- 空间局部性(Spatial locality): 某个内存区域被访问,很可能稍后其临近的区域也会被访问;
接下来就来看下cache是怎么构成的。
缓存架构
下图是一个有256 (2^8) 个缓存行,4KB(2^10)大小的cache架构框图,可以看到,cache由两部分组成:cache controller,以及cache memory; cache memory是由一内存单元阵列组成的专用存储结构,其中每一个存储单元被称为cache lines(缓存行);而cache controller负责将CPU发送过来的地址映射到cache memory,选取相应的cache memory:
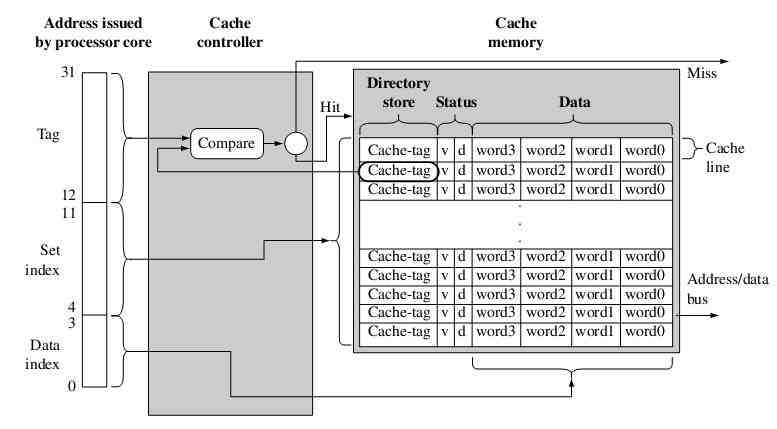
图片来自《ARM System Develop’s Guide - Designing and Optimizting System Software》
一个cache line由三个部分组成:目录项,数据区以及状态。目录项也叫作cache tag,用于标识一个cache line是主内存中的来源(地址);而从主内存中拷贝过来的数据则保持在数据区,而状态位则用于保持cache line的状态信息,通常有valid(有效)跟dirty(脏数据)两种状态。有效则意味着缓存数据保持的是最新的主内存数据,而脏数据则表示一个缓存行中的数据跟主内存不同。
CPU有数据或者指令请求时,首先被cache controller截取,controller会把内存地址分为三个部分:tag标签域,set index集合索引域,data index数据索引域。利用set index来定位可能包含内存数据的缓存行。刚才我们说道,每个缓存行都有个一个cache tag,controller正是通过这个标签域与状态位来确定数据是否存在。如果一个缓存行的状态为是valid,并且内存地址的tag与缓存行的tag相同,则命中缓存(cache hit),否则出现缓存缺失(cache miss)。
- cache miss: 出现缓存缺失,cache controller需要将主内存中的数据拷贝到缓存中,并将其提供给CPU;
- cache hit: 缓存命中,直接将命中缓存数据发送给CPU(利用
data index确定数据所在位置);
那么,主内存是如何映射到cache当中的了?从数学集合的角度来看,两个集合的映射一般有一对一,多对一、一对多、多对多等几种形式。与此相类似,主内存与cache直接的物理映射(通过硬件设计实现)大致有三种形式:
- Directed Mapping(直接映射): 对于主内存中的任一地址仅有一个可能的cache地址。这种映射方式最为简单,其存在的不足之处容易出现“缓存抖动”(cache thrashing) - 不断出现缓存缺失,从而降低系统性能;
- Full-associative cache(全关联): 对每个主内存中的地址可以映射到任何一个cache位置。全关联虽然为主内存数据的存储带来了更多的灵活性,但是由于其实现方式复杂,成本高,因而通常只在cache空间很小的CPU中使用;
- K-way assocative cache(多路关联):是直接映射与全关联两种方式的折中策略,通过将cache memory划分为更小的单位(
ways),使得主内存中的位置可能有多个cache位置与之相对应。比如下图是一个4-way 4KB大小的cache示意图:
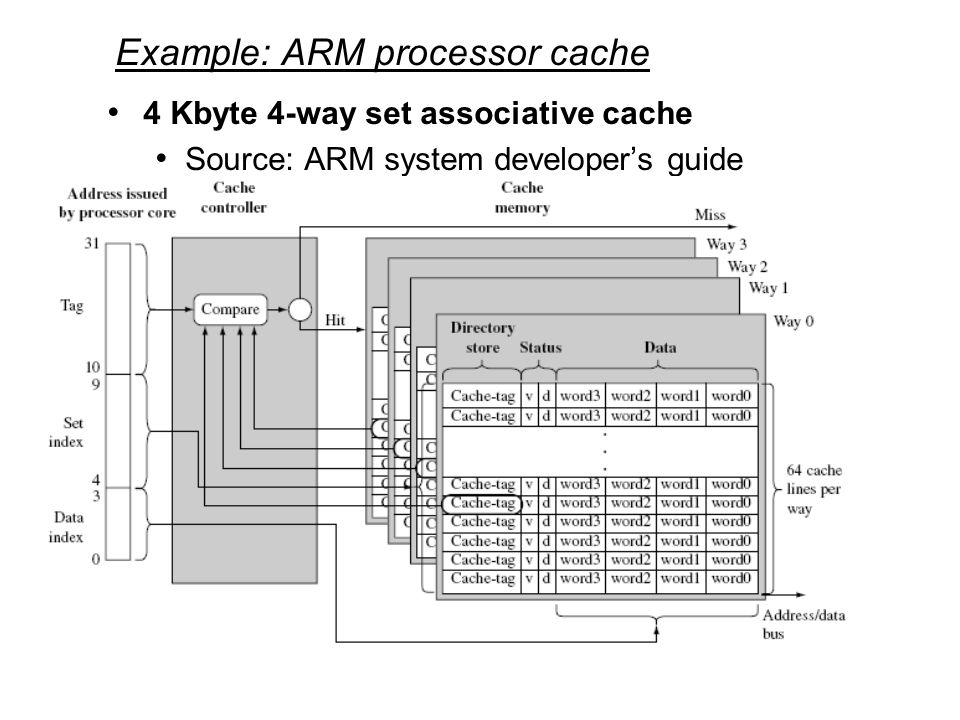
图片来自《ARM System Develop’s Guide - Designing and Optimizting System Software》
与前文中的示意图不同的是,这里cache memory共包含了4路,每路都包含了64(2^6)个缓存行,但cache总的大小仍然是4KB(4*4*64*4 bytes),但现在对于每个set index都对应了4个cache line,这4个缓存行可以看成是一个set,这也是set index这个名字的由来。
缓存策略
这里就来看下缓存的两种策略: 写内存以及缓存替换策略。写内存策略用于确定何时将数据写入内存;但出现cache miss时,使用替换策略将某个缓存行换出。
首先来看下写策略。
write policy
当CPU需要将数据写回主内存时,cache controller有两种写策略可选择:一种是同时更新缓存行数据和主内存数据,这种方法被称为write-through;另一种策略write-back则只更新缓存行数据,而不更新主内存数据。
- Writethrough: 如果缓存命中,则同时更新主内存与缓存行数据,确保主内存与缓存数据始终保持一致,由于需要将数据写回内存,因此
write-through会比write-back慢; - Writeback: 使用该写策略,只更新有效(缓存行标记为valid)的缓存数据,而不更新主内存,这样就可能出现缓存与主内存数据不一致,那么,何时将缓存数据写入内存了?当cache controller写数据到缓存时,将该缓存行中的数据标记为
dirty,等到下一次访问时,controller知道这个缓存行数据并不在内存中,因此换出该缓存行时,则自动将其写回主内存;
replacement policy
出现cache miss时,cache controller需要从缓存中选择一个缓存行用于保存从主内存中加载的新数据。如果被替换的缓存行包含了有效或者脏数据,则需要将其写回内存。那么,如何从缓存中选择可能被替换的缓存行了?这就是缓存的替换策略。一般有以下几种:
- Least Recently Used(LRU): 将最少使用的缓存行换出;
- Roud-robin(RR): 轮盘随机选择一个缓存行换出;
更多关于缓存替换策略可以参考WIKIPEDIA文章:https://en.wikipedia.org/wiki/Cache_replacement_policies。
总结
目前大多数计算机系统都使用多级的缓存结构, 使用多级缓存好处是改善了缓存命中率, 但同时需要考虑各个缓存(L1/L2/L3)数据的同步与一致性问题参考Wikipedia Cache Coherence, 增加了硬件设计的复杂度. 对CPU cache来说, 需要考虑如下几个问题:
- cache的结构: 每个cache line的大小是多少, 具体是如何存放的?
- 如何找到一个cache项: 如何通过给定的内存地址找到对应的cache line, 这里就需要建立cache与主存之间的映射关系, 通常有直接映射(direct mapped), 多路关联(full-way associcative)以及全关联(fully associative)
- 发生cache miss(缓存缺失)时要如何进行替换: 一般有最少使用(Least Recently Used, LRU)以及随机选择(random)两种方法.
- 如何同步cache与主存之间的数据: 一般来说有回写(write-back)与直写(write-through)两种策略.
参考文献
- http://service.scs.carleton.ca/sivarama/org_book/org_book_web/slides/chap_1_versions/ch17_1.pdf
- https://www.cs.umd.edu/class/fall2001/cmsc411/proj01/cache/cache.pdf
- http://www.ece.northwestern.edu/~kcoloma/ece361/lectures/Lec14-cache.pdf
- https://cseweb.ucsd.edu/classes/fa14/cse240A-a/pdf/08/CSE240A-MBT-L15-Cache.ppt.pdf
- http://people.cs.pitt.edu/~cho/cs1541/current/handouts/lect-memh_4up.pdf
- 《ARM System Develop’s Guide - Designing and Optimizting System Software》
- 与程序员相关的CPU缓存知识
- CPU cache